Instead of confusing by explanation, I'll let the code explain what I'm trying to achieve
I'm comparing a combination in one dataframe with another. The 2 dataframes has the following:
- an address
- the string of the articles from which it was extracted (in a list format)
I WANT TO FIND : address-article combination within one file, say reg, that's not present in the other look. The df names refer to the method the addresses were extracted from the articles.
Note: The address when written 'AZ 08' and '08 AZ' should be treated the same.
reg = pd.DataFrame({'Address': {0: 'AZ 08',1: '04 CA',2: '10 FL',3: 'NY 30'},
'Article': {0: '[\'Location AZ 08 here\', \'Went to 08 AZ\']',
1: '[\'Place 04 CA here\', \'Going to 04 CA\', \'Where is 04 CA\']',
2: '[\'This is 10 FL \', \'Coming from FL 10\']',
3: '[\'Somewhere around NY 30\']'}})
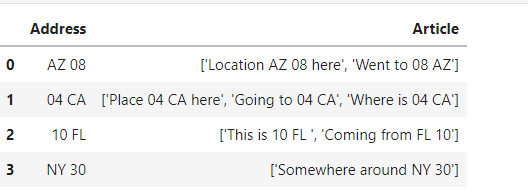
look = pd.DataFrame({'Address': {0: 'AZ 08',1: '04 CA',2: 'NY 30' },
'Article': {0: '[\'Location AZ 08 here\']',
1: '[\'Place 04 CA here\', \'Going to 04 CA\', \'Where is 04 CA\']',
2: '[\'Somewhere around NY 30\', \'Almost at 30 NY\']'}})

What i did (able to) find is, the records in which there is a mismatch. But unable to get a address - location level info. My method shown below.
def make_set_expanded(string,review):
rev_l = ast.literal_eval(review)
s = set(str(string).lower().split())
s.update(rev_l)
return s
reg_list_expand = reg.apply(lambda x: make_set_expanded(x['Address'], x['Article']), axis=1).to_list()
look_list_expand = look.apply(lambda x: make_set_expanded(x['Address'], x['Article']), axis=1).to_list()
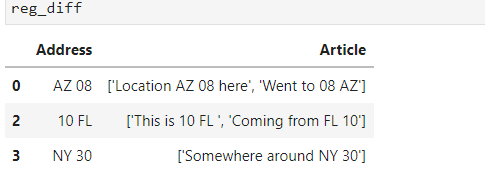
reg_diff = reg[reg.apply(lambda x: 'Yes' if make_set_expanded(x['Address'], x['Article']) in look_list_expand else 'No', axis=1) == 'No']
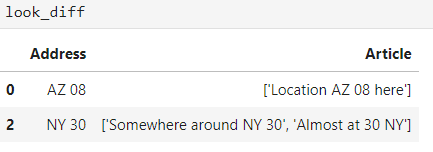
look_diff = look[look.apply(lambda x: 'Yes' if make_set_expanded(x['Address'], x['Article']) in reg_list_expand else 'No', axis=1) == 'No']
The functions, in overall :
- treates an address 'AZ 08' and '08 AZ' as the same
- shows missing addresses.
- shows addresses which came from a diferent article
But instead of showing the whole list as is (i.e including the ones which already has a match), I would like to show only the particular combination thats missing.
For eg in : in reg_diff, instead of showing the whole set again, i'd like to see only the address-article combination :
'AZ 08': 'Went to 08 AZ' in the row.
CodePudding user response:
IIUC, try:
- convert your "Article" column from string to list
explodeto get each article in a separate row.- outer
mergewithindicator=Trueto identify which DataFrame each row comes from - filter the merged dataframe to get the required output.
reg["Article"] = reg["Article"].str[1:-1].str.split(", ")
reg = reg.explode("Article")
look["Article"] = look["Article"].str[1:-1].str.split(", ")
look = look.explode("Article")
merged = reg.merge(look, how="outer", indicator=True)
reg_diff = merged[merged["_merge"].eq("left_only")].drop("_merge", axis=1)
look_diff = merged[merged["_merge"].eq("right_only")].drop("_merge", axis=1)
>>> reg_diff
Address Article
1 AZ 08 'Went to 08 AZ'
5 10 FL 'This is 10 FL '
6 10 FL 'Coming from FL 10'
>>> look_diff
Address Article
8 NY 30 'Almost at 30 NY'
CodePudding user response:
I'm not fully sure what your logic is looking to do, so I'll start with some example methods that may be useful:
Example of how to use .apply(eval) to format the text as lists. And an example of using .explode() to make those lists into rows.
def format_df(df):
df = df.copy()
df.Article = df.Article.apply(eval)
df = df.explode("Article")
return df.reset_index(drop=True)
reg, look = [format_df(x) for x in [reg, look]]
print(reg)
print(look)
Output:
Address Article
0 AZ 08 Location AZ 08 here
1 AZ 08 Went to 08 AZ
2 04 CA Place 04 CA here
3 04 CA Going to 04 CA
4 04 CA Where is 04 CA
5 10 FL This is 10 FL
6 10 FL Coming from FL 10
7 NY 30 Somewhere around NY 30
Address Article
0 AZ 08 Location AZ 08 here
1 04 CA Place 04 CA here
2 04 CA Going to 04 CA
3 04 CA Where is 04 CA
4 NY 30 Somewhere around NY 30
5 NY 30 Almost at 30 NY
Example of packing rows back into lists:
reg = reg.groupby('Address', as_index=False).agg(list)
look = look.groupby('Address', as_index=False).agg(list)
print(reg)
print(look)
Output:
Address Article
0 04 CA [Place 04 CA here, Going to 04 CA, Where is 04...
1 10 FL [This is 10 FL , Coming from FL 10]
2 AZ 08 [Location AZ 08 here, Went to 08 AZ]
3 NY 30 [Somewhere around NY 30]
Address Article
0 04 CA [Place 04 CA here, Going to 04 CA, Where is 04...
1 AZ 08 [Location AZ 08 here]
2 NY 30 [Somewhere around NY 30, Almost at 30 NY]