I can read text from an image using OCR. However, it works line by line.
I want to now group text based on solid lines surrounding the text.
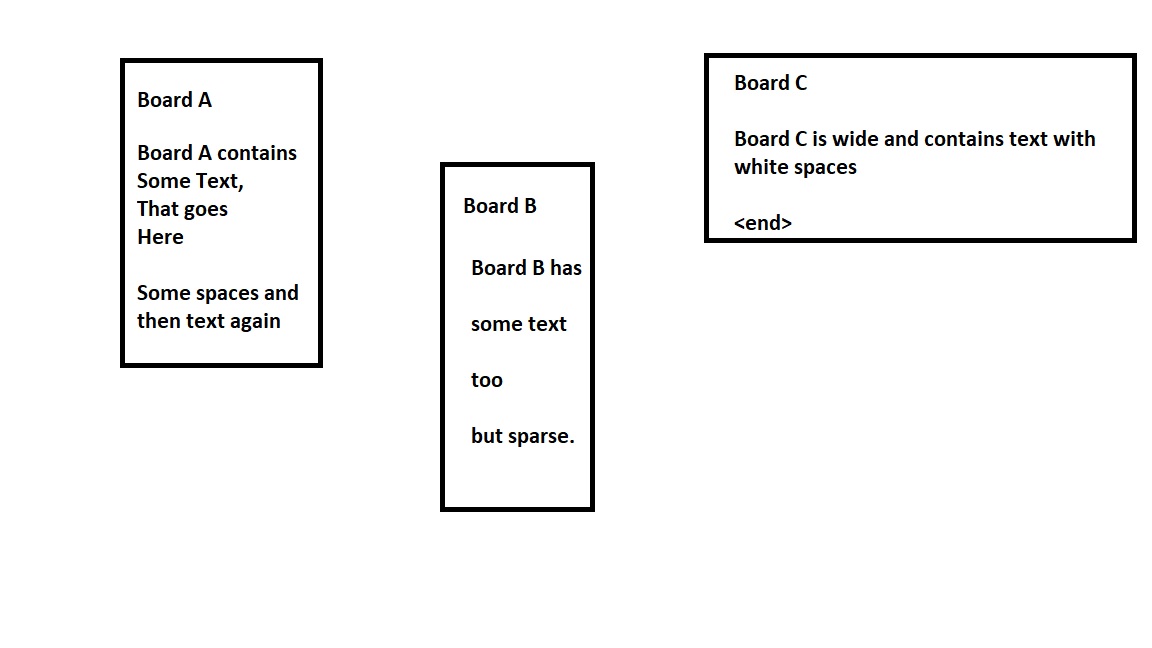
For example, consider I have below rectangle banners. I can read text line by line. Fine! Now I want to group them by Board A,B,C and hold them in some data structure, so that I can identify, which lines belong to which board. It is given that images would be diagrams like this with solid lines around each block of text.
Please guide me on the right approach.
CodePudding user response:
As mentioned in the comments by Yunus, you need to crop sub-images and feed them to an OCR module individually. An additional step could be ordering of the contours.
Approach:
- Obtain binary image and invert it
- Find contours
- Crop sub-images based on the bounding rectangle for each contour
- Feed each sub-image to OCR module (I used
easyocrfor demonstration) - Store text for each board in a dictionary
Code:
# Libraries import
import cv2
from easyocr import Reader
reader = Reader(['en'])
img = cv2.imread('board_text.jpg',1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# inverse binary
th = cv2.threshold(gray,127,255,cv2.THRESH_BINARY_INV cv2.THRESH_OTSU)[1]
# find contours and sort them from left to right
contours, hierarchy = cv2.findContours(th, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
contours = sorted(contours, key=lambda x: [cv2.boundingRect(x)[0], cv2.boundingRect(x)[1]])
#initialize dictionary
board_dictionary = {}
# iterate each contour and crop bounding box
for i, c in enumerate(cnts):
x,y,w,h = cv2.boundingRect(c)
crop_img = img[y:y h, x:x w]
# feed cropped image to easyOCR module
results = reader.readtext(crop_img)
# result is output per line
# create a list to append all lines in cropped image to it
board_text = []
for (bbox, text, prob) in results:
board_text.append(text)
# convert list of words to single string
board_para = ' '.join(board_text)
#print(board_para)
# store string within a dictionary
board_dictionary[str(i)] = board_para
Dictionary Output:
board_dictionary {'0': 'Board A Board A contains Some Text, That goes Here Some spaces and then text again', '1': 'Board B Board B has some text too but sparse.', '2': 'Board €C Board C is wide and contains text with white spaces '}
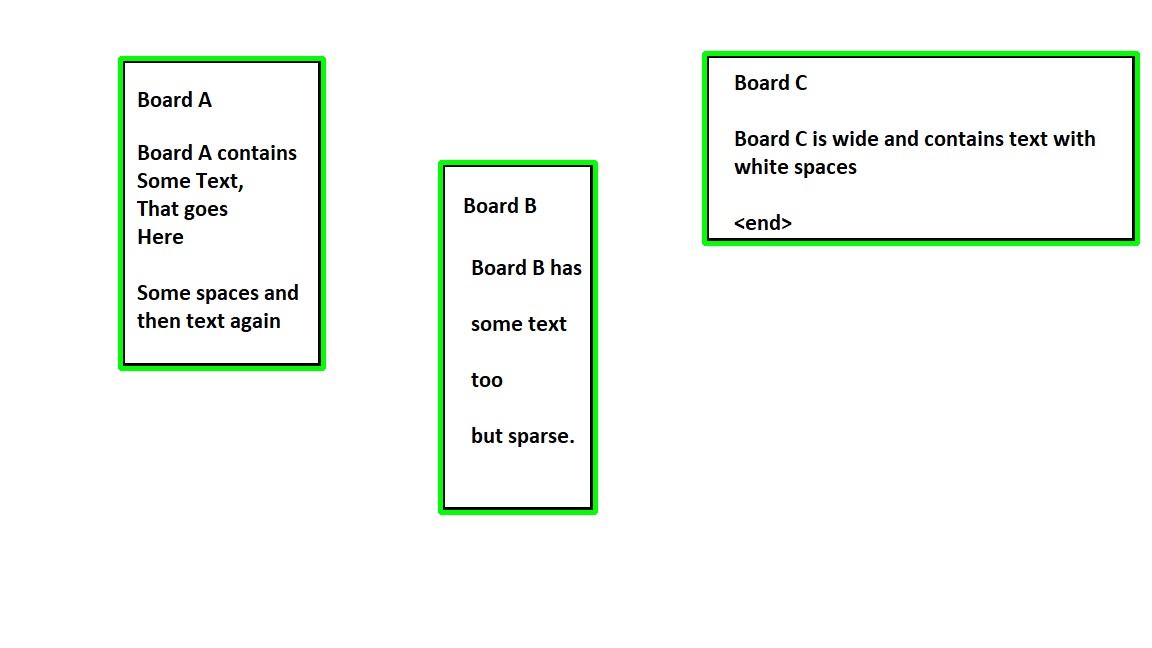
Drawing each contour
img2 = img.copy()
for i, c in enumerate(cnts):
x,y,w,h = cv2.boundingRect(c)
img2 = cv2.rectangle(img2, (x, y), (x w, y h), (0,255,0), 3)
Note:
- While working on different images make sure the ordering is correct.
- Choice of OCR module is yours
pytesseractandeasyocrare the options I know.
CodePudding user response:
This can be done by performing following steps:
- Find the shapes.
- Compute the shape centers.
- Find the text boxes.
- Compute the text boxes centers.
- Associate the textboxes with shapes based on distance.
The code is as follows:
import cv2
from easyocr import Reader
import math
shape_number = 2
image = cv2.imread("./ueUco.jpg")
deep_copy = image.copy()
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(image_gray, 150, 255, cv2.THRESH_BINARY)
thresh = 255 - thresh
shapes, hierarchy = cv2.findContours(image=thresh, mode=cv2.RETR_EXTERNAL, method=cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(image=deep_copy, contours=shapes, contourIdx=-1, color=(0, 255, 0), thickness=2, lineType=cv2.LINE_AA)
shape_centers = []
for shape in shapes:
row = int((shape[0][0][0] shape[3][0][0])/2)
column = int((shape[3][0][1] shape[2][0][1])/2)
center = (row, column, shape)
shape_centers.append(center)
# cv2.imshow('Shapes', deep_copy)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
languages = ['en']
reader = Reader(languages, gpu = True)
results = reader.readtext(image)
def cleanup_text(text):
return "".join([c if ord(c) < 128 else "" for c in text]).strip()
for (bbox, text, prob) in results:
text = cleanup_text(text)
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
column = int((tl[0] tr[0])/2)
row = int((tr[1] br[1])/2)
center = (row, column, bbox)
distances = []
for iteration, shape_center in enumerate(shape_centers):
shape_row = shape_center[0]
shape_column = shape_center[1]
dist = int(math.dist([column, row], [shape_row, shape_column]))
distances.append(dist)
min_value = min(distances)
min_index = distances.index(min_value)
if min_index == shape_number:
cv2.rectangle(image, tl, br, (0, 255, 0), 2)
cv2.putText(image, text, (tl[0], tl[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
cv2.imwrite(f"image_{shape_number}.jpg", image)
cv2.destroyAllWindows()
The output looks like this.
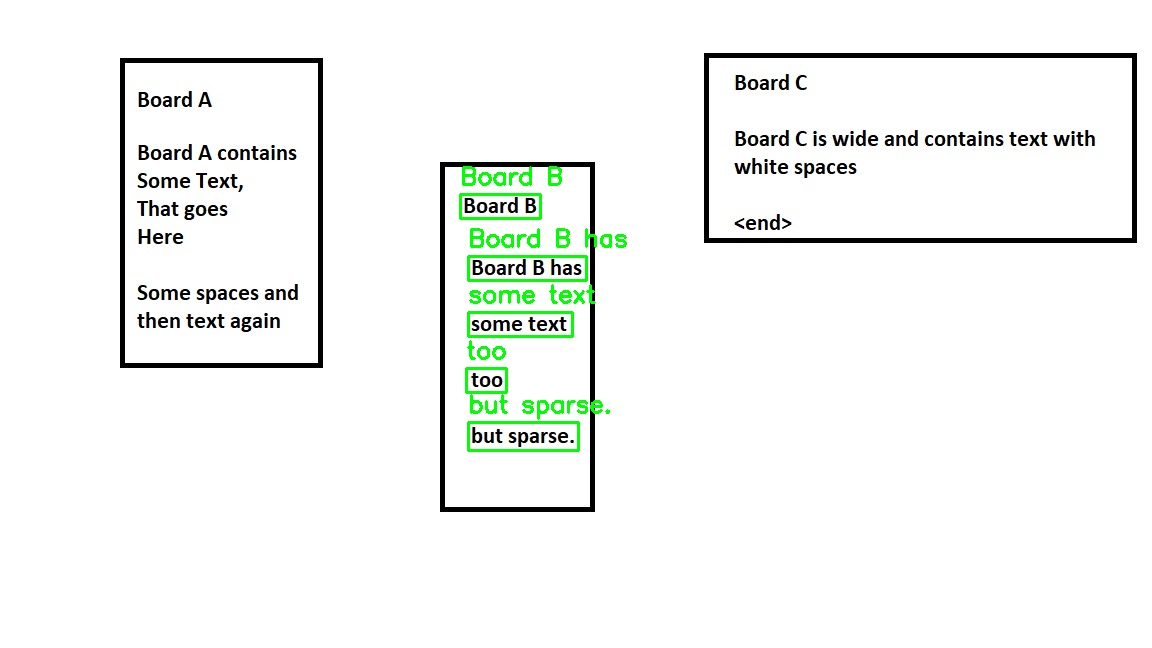
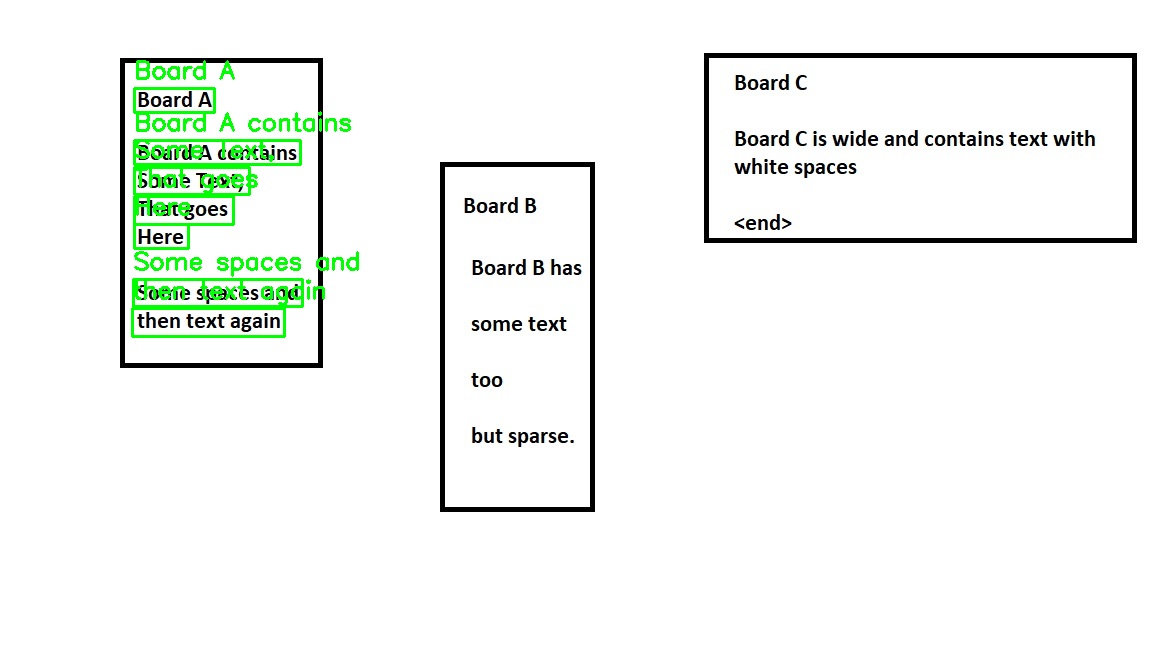
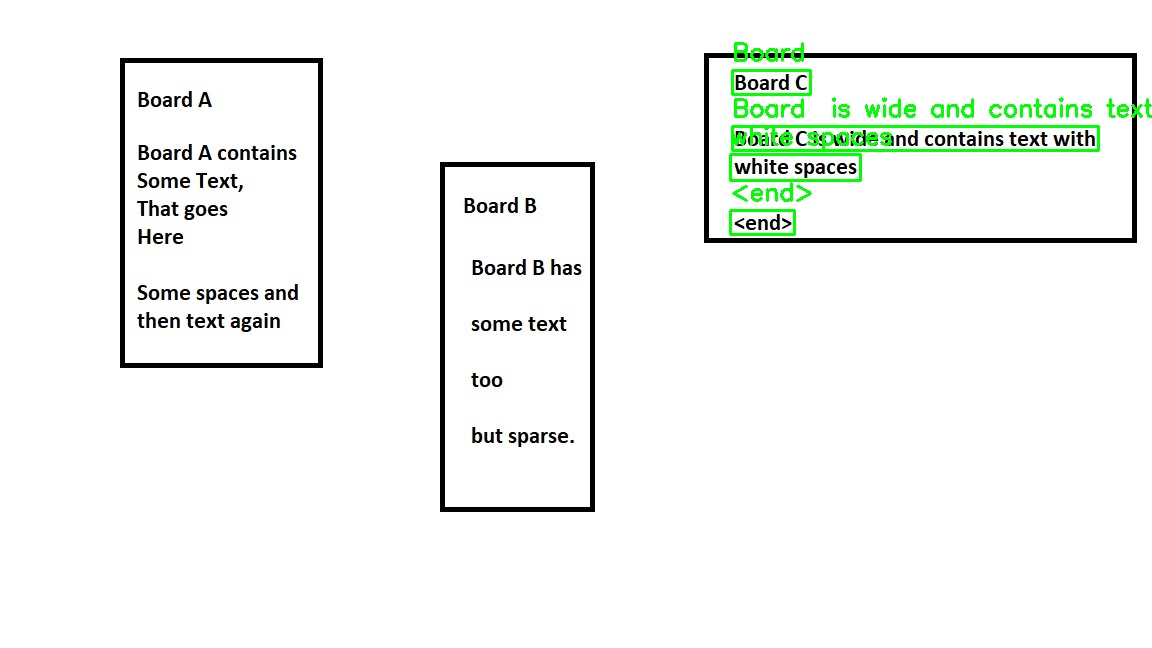
Please note that this solution is almost complete. You just have to compute the text embodied in each shape and put it in your desired data structure.
Note: shape_number represents the shape that you want to consider.
There is another solution that I would like you to work on.
- Find all the text boxes.
- Compute the centers for text boxes.
- Run k-means clustering on the centers.
I would prefer the second solution but for the time being, I implemented the first one.