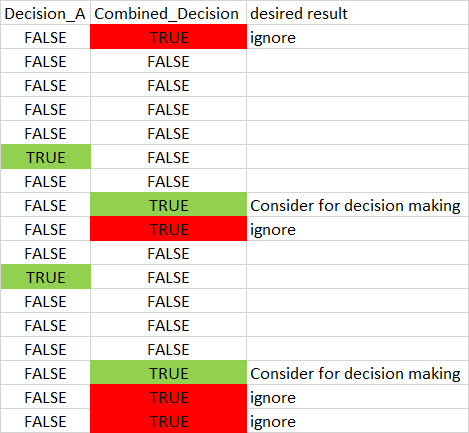
So, for these 2 columns, [Decision_A], [Combined_Decision], is there a way that I only take first occurrence of [Combined_Decision] == TRUE while subsequent "TRUE" can be ignored until next "TRUE" appears in [Decision_A] in pandas dataframe?
Dataframe columns be like
CodePudding user response:
Just iterate over all of the rows while checking for the appropriate conditions. Use some sort of flag to maintain whether there has been a True in the first column since the last desired result.
The following self-contained example should achieve roughly what you want, putting a 1 in the desired_result column if conditions are met. The way I implemented it, if there are True values in both cells of the same row, this yields a desired result.
import pandas as pd
df = pd.DataFrame({'Decision_A': [False, False, False, True, False, False, True, False, False],
'Combined_Decision': [True, False, False, False, True, False, True, True, True]})
A_flag = False
df['desired_result'] = 0
for i, row in df.iterrows():
if row['Decision_A'] == True:
A_flag = True
if A_flag == True and row['Combined_Decision'] == True:
A_flag = False
df.loc[i, 'desired_result'] = 1
print(df)
gives
Decision_A Combined_Decision desired_result
0 False True 0
1 False False 0
2 False False 0
3 True False 0
4 False True 1
5 False False 0
6 True True 1
7 False True 0
8 False True 0
P.S. Making good reproducible examples for pandas questions will likely get you answers more quickly here.