I have a table with a column with list of dictionaries. I need to first split the list of dictionaries to each dictionary in a separate column. In the next step, I need to convert the dictionary to their respective columns, while melting the dataframe. An breakdown of steps is given below-
Step 1-

Step 2-
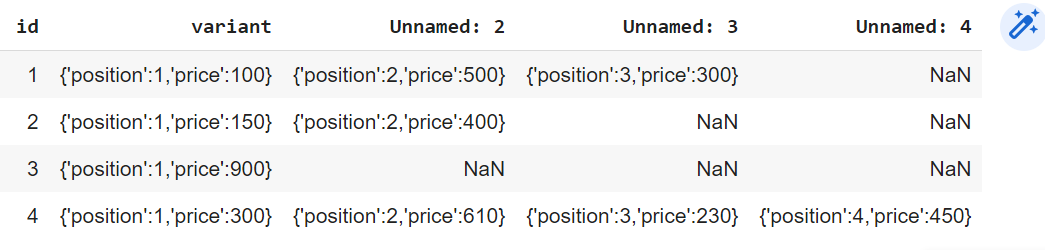
Step 3 (Output)-
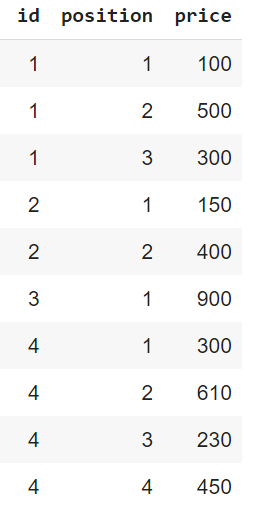
CodePudding user response:
Use nested list comprehension for list of dictionaries and then pass to DataFrame constructor:
df = pd.DataFrame({'id':[1,2], 'variant':[[{'position':1, 'price':100}, {'position':2, 'price':500},
{'position':3, 'price':300}],
[ {'position':1, 'price':150}, {'position':2, 'price':400}]]})
print (df)
id variant
0 1 [{'position': 1, 'price': 100}, {'position': 2...
1 2 [{'position': 1, 'price': 150}, {'position': 2...
L = [{**{'id':x},**z} for x, y in zip(df['id'], df['variant']) for z in y]
df2 = pd.DataFrame(L)
Or DataFrame.explode with json_normalize:
df1 = df.explode('variant').reset_index(drop=True)
df2 = df1[['id']].join(pd.json_normalize(df1['variant']))
print (df2)
id position price
0 1 1 100
1 1 2 500
2 1 3 300
3 2 1 150
4 2 2 400
If solution above return:
TypeError: 'str' object is not a mapping
because there are strings solution is:
df = pd.DataFrame({'id':[1,2], 'variant':["[{'position':1, 'price':100}, {'position':2, 'price':500}, {'position':3, 'price':300}]",
"[ {'position':1, 'price':150}, {'position':2, 'price':400}]"]})
print (df)
id variant
0 1 [{'position':1, 'price':100}, {'position':2, '...
1 2 [ {'position':1, 'price':150}, {'position':2, ...
import ast
L = [{**{'id':x},**z} for x,y in zip(df['id'], df['variant']) for z in ast.literal_eval(y)]
df2 = pd.DataFrame(L)
print (df2)
id position price
0 1 1 100
1 1 2 500
2 1 3 300
3 2 1 150
4 2 2 400
Performance in 10k rows:
df = pd.DataFrame({'id':[1,2], 'variant':[[{'position':1, 'price':100}, {'position':2, 'price':500},
{'position':3, 'price':300}],
[ {'position':1, 'price':150}, {'position':2, 'price':400}]]})
df = pd.concat([df] * 5000, ignore_index=True)
#keramat solution
In [23]: %%timeit
...: df.explode('variant').apply({'variant':lambda x: pd.Series(x), 'id': lambda x: pd.Series(x)}).droplevel(0, axis = 1).rename(columns={'position':'position', 'price':'price', 0:'id'})
...:
14.2 s ± 505 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [24]: %%timeit
...: df1 = df.explode('variant').reset_index(drop=True)
...:
...: df1[['id']].join(pd.json_normalize(df1['variant']))
...:
...:
180 ms ± 4.06 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [25]: %%timeit
...: pd.DataFrame([{**{'id':x},**z} for x, y in zip(df['id'], df['variant']) for z in y])
...:
...:
52.3 ms ± 2.76 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
CodePudding user response:
Use:
df.explode('variant').apply({'id': lambda x: x, 'variant':lambda x: pd.Series(x)}).droplevel(0, axis = 1)
Output:
id position price
0 1 1 100
0 1 2 500
0 1 3 300
1 2 1 150
1 2 2 400