I have a data balancing problem at hand wherein I have images which have multiple classes i.e. each image can have multiple class or one class. I have the label file which has all the classes named from A to G and fn(image name) as the columns. Each column has a value 0 or 1,wherein 0 means that class is absent in image and 1 means that particular class is present in the image. Now, I want to subset the dataframe in such a manner that I get different dataframes each with combinations of different classes 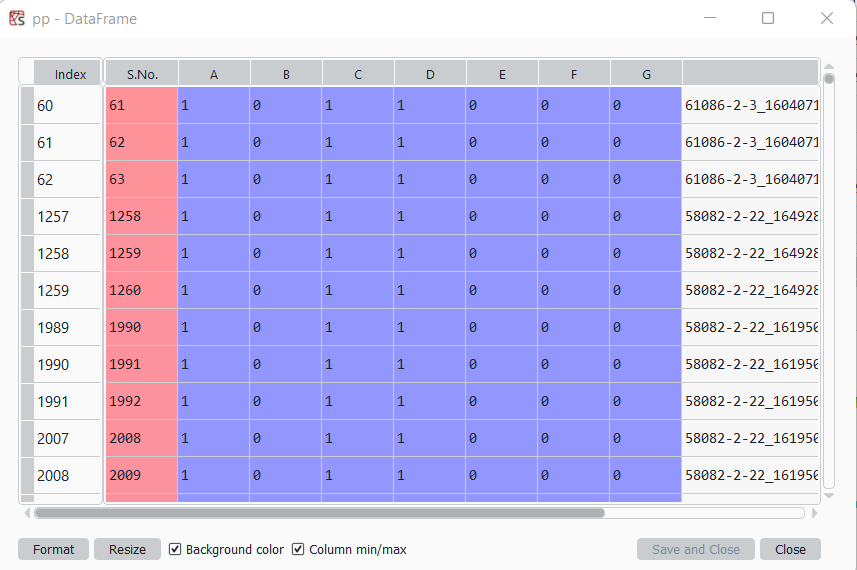
The issue is if I use the multiple conditions with the dataframe command such as (here pp is used to denote dataframe :
pp_A_B=pp[(pp['A']==1) & (pp['B']==1) & (pp['C']==0) & (pp['D']==0) & (x['E']==0) & (x['F']==0) &(pp['G']==0)]
Here,pp_A_B gives me the dataframe having images which have only A and B classes.
I will have to write multiple variables to know about the various combinations.Kindly help how can we automate it to get all the possible combinations in a faster manner.
CodePudding user response:
Hi you should use the groupyby and get_group methods to extract the desired elements.
Here is an example if you are trying to get datas where A = 0 & B= 0 :
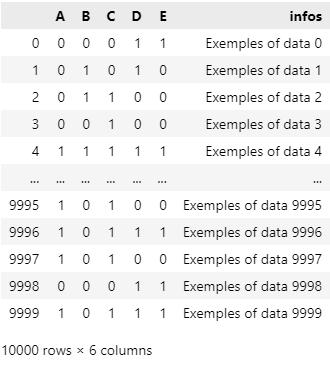
#Simulation of your datas
nb_rows = 10000
nb_colums = 5
df_array = np.random.randint(0,2, size =(nb_rows, nb_colums))
df = pd.DataFrame(df_array)
df.columns = ["A", "B", "C", "D", "E"]
df["infos"] = [f"Exemples of data {i}" for i in range(len(df))]
UPDATE :
And now the use of the mentioned methods :
df.groupby(["A", "B"]).get_group((0, 0))
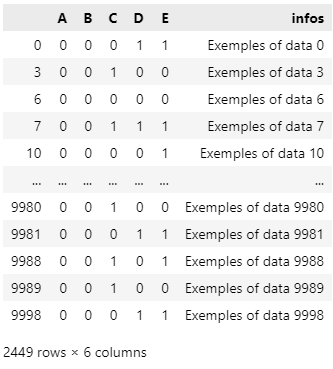
Here you easily find all the data that meet A = 0 & B = 0.
Now you can iterate thought all of your targeted columns combinations this way :
columns_to_explore = ["A", "B", "C"]
k = [0]*len(columns_to_explore)
for i in range(2**len(columns_to_explore)):
i_binary = str(bin(i)[2:])
i_binary = "".join(["0" for _ in range(len(columns_to_explore)-len(i_binary))]) i_binary
list_values = [int(x) for x in i_binary]
df_selected = df.groupby(columns_to_explore).get_group(tuple(list_values))
#Do something then ...
CodePudding user response:
Let us suppose you have the following data frame:
import pandas as pd
import random
attr = [0, 1]
N = 10000
rg = range(N)
df = pd.DataFrame(
{
'A': [random.choice(attr) for i in rg],
'B': [random.choice(attr) for i in rg],
'C': [random.choice(attr) for i in rg],
'D': [random.choice(attr) for i in rg],
'E': [random.choice(attr) for i in rg],
'F': [random.choice(attr) for i in rg],
'G': [random.choice(attr) for i in rg],
}
)
and that you want to store all data frame combinations in a list. Then, you can write the following function to get all indices that correspond to the same combination of 0 and 1:
import random
from numba import njit
@njit
def _get_index_combinations(possible_combinations, values):
index_outpus = []
for combination in possible_combinations:
mask = values == combination
_temp = []
for i in range(len(mask)):
if mask[i].all():
_temp.append(i)
index_outpus.append(_temp)
return index_outpus
possible_combinations = df.drop_duplicates().values
index_outpus = _get_index_combinations(possible_combinations, df.values)
Finally, you can decompose the data frame in chunks by iterating over all index combinations:
sliced_dfs = [df.loc[df.index.isin(index)] for index in index_outpus]
If you then, for instance, run
print(sliced_dfs[0])
you will get a query for one possible combination.
Note:
You can even go further an really create several data frames (not stored in a list) for all possible combinations. If you go dirty and use something like this:
col_names = "ABCDEFG"
final_output = {"all_names": [], "all_querys": []}
for numerator, i in enumerate(possible_combinations):
df_name = ""
col_pos = np.where(i)[0]
for pos in col_pos:
df_name = col_names[pos]
final_output["all_names"].append(f"df_{df_name}")
query_code = f"df_{df_name} = df.loc[df.index.isin({index_outpus[numerator]})]"
final_output["all_querys"].append(query_code)
exec(query_code)
It creates you a dictionary named final_output. There, the names of all created data frames are stored. For example:
{'all_names': ['df_ABG', 'df_G', 'df_AC', ...], 'all_querys': [...]}
You can then just print all frames in all_names, for example df_ABG, which returns you:
A B C D E F G
0 1 1 0 0 0 0 1
59 1 1 0 0 0 0 1
92 1 1 0 0 0 0 1
207 1 1 0 0 0 0 1
211 1 1 0 0 0 0 1
284 1 1 0 0 0 0 1
321 1 1 0 0 0 0 1
387 1 1 0 0 0 0 1
415 1 1 0 0 0 0 1
637 1 1 0 0 0 0 1
....