My dataset shape is (248857, 11)
This is how it looks like before StandartScaler. I performed clustering analysis because of those clustering algorithms such as K-means do need feature scaling before they are fed to the algo.
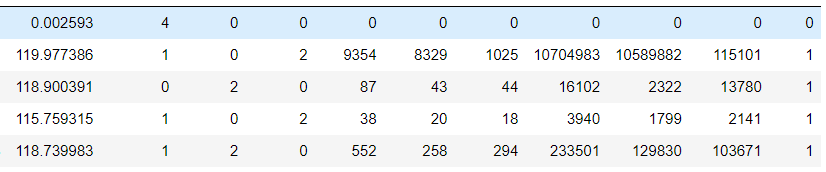
After

I performed K-Means with three clusters and I am trying to find a way to show these clusters. I found T-SNE as a solution but I am stuck. This is how I implemented it:
# save the clusters into a variable l.
l = df_scale['clusters']
d = df_scale.drop("clusters", axis = 1)
standardized_data = StandardScaler().fit_transform(d)
# TSNE Picking the top 100000points as TSNE
data_points = standardized_data[0:100000, :]
labels_80 = l[0:100000]
model = TSNE(n_components = 2, random_state = 0)
tsne_data = model.fit_transform(data_points)
# creating a new data frame which help us in ploting the result data
tsne_data = np.vstack((tsne_data.T, labels_80)).T
tsne_df = pd.DataFrame(data = tsne_data,
columns =("Dimension1", "Dimension2", "Clusters"))
# Ploting the result of tsne
sns.FacetGrid(tsne_df, hue ="Clusters", size = 6).map(
plt.scatter, 'Dimension1', 'Dimension2').add_legend()
plt.show()
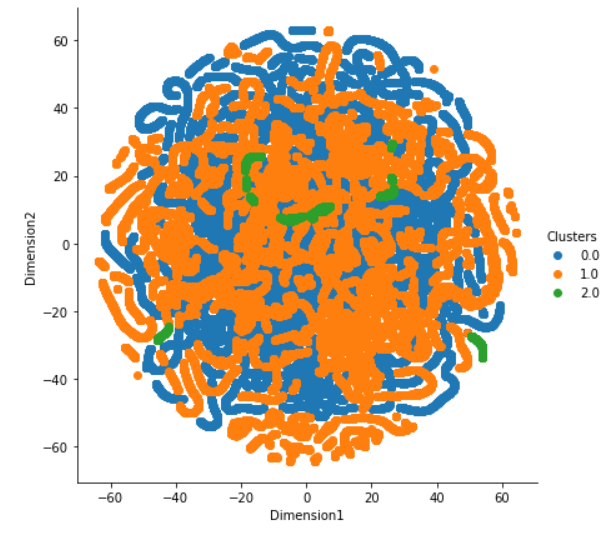
As you see, it is not that good. Can you help to visualize this better, please?
CodePudding user response:
It seems you need to play with the perplexity hyper-parameter which is:
a tunable parameter that says (loosely) how to balance attention between local and global aspects of your data. The parameter is, in a sense, a guess about the number of close neighbors each point has. The perplexity value has a complex effect on the resulting pictures.
Read more about it in this post and more specifically, here.