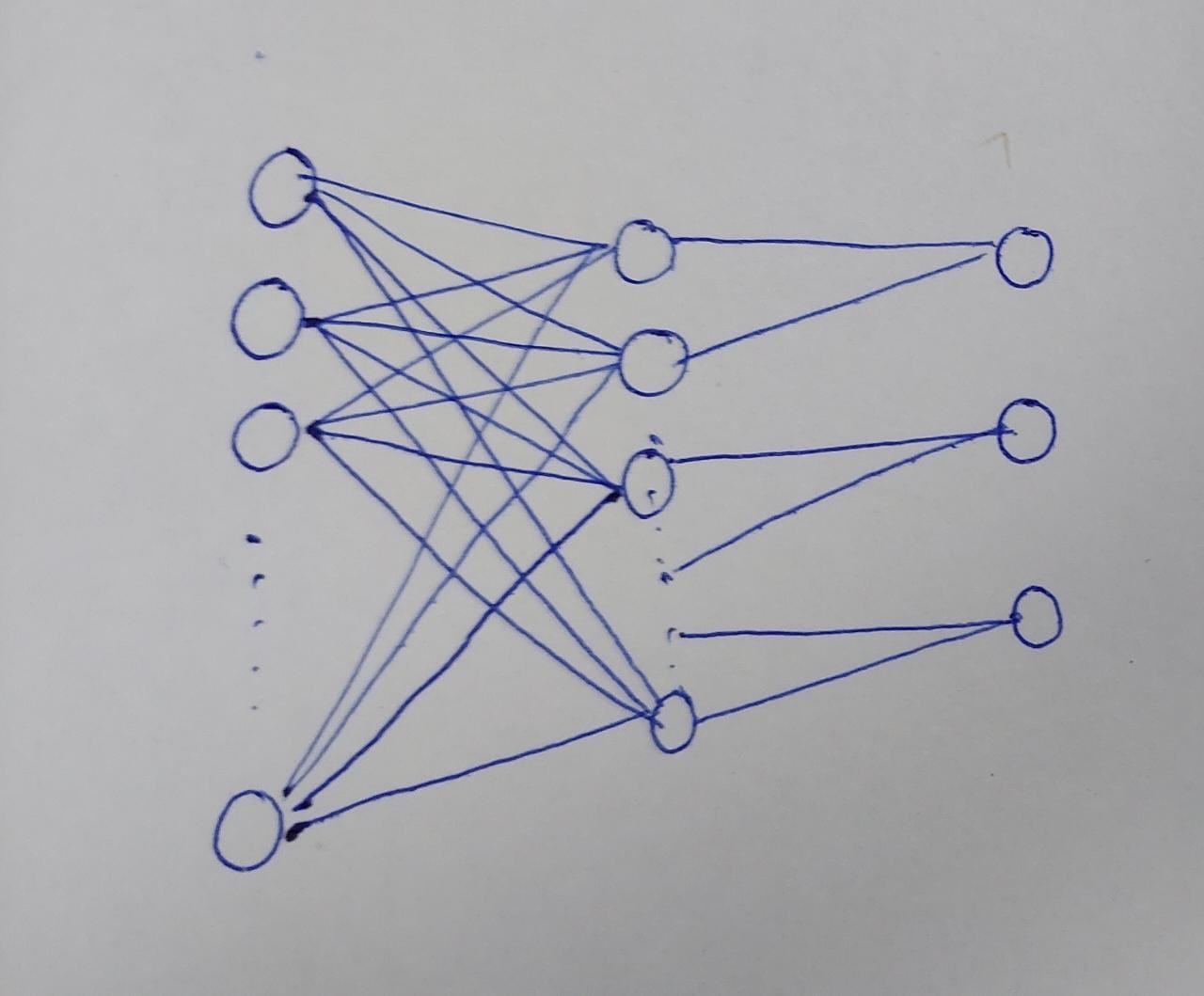
As shown in the figure, it is a 3 layer with NN, namely input layer, hidden layer and output layer. I want to design the NN(in PyTorch, just the arch) where the input to hidden layer is fully-connected. However, from hidden layer to output, the first two neurons of the hidden layer should be connected to first neuron of the output layer, second two should be connected to the second in the output layer and so on. How shall this should be designed ?
from torch import nn
layer1 = nn.Linear(input_size, hidden_size)
layer2 = ??????
CodePudding user response:
As @Jan said here, you can overload nn.Linear and provide a point-wise mask to mask the interaction you want to avoid having. Remember that a fully connected layer is merely a matrix multiplication with an optional additive bias.
Looking at its source code, we can do:
class MaskedLinear(nn.Linear):
def __init__(self, *args, mask, **kwargs):
super().__init__(*args, **kwargs)
self.mask = mask
def forward(self, input):
return F.linear(input*self.mask, self.weight, self.bias)
Having F defined as torch.nn.functional
Considering the constraint you have given to the second layer:
the first two neurons of the hidden layer should be connected to the first neuron of the output layer
It seems you are looking for this pattern:
tensor([[1., 0., 0.],
[1., 0., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.]])
Which can be obtained using torch.block_diag:
mask = torch.block_diag(*[torch.ones(2,1),]*output_size)
Having this, you can define your network as:
net = nn.Sequential(nn.Linear(input_size, hidden_size),
MaskedLinear(hidden_size, output_size, mask))
If you feel like it you can even implement it inside the custom layer:
class LocalLinear(nn.Linear):
def __init__(self, kernel_size=2, *args, mask, **kwargs):
super().__init__(*args, **kwargs)
assert self.in_features == kernel_size*self.out_features
self.mask = torch.block_diag(*[torch.ones(kernel_size,1),]*self.out_features)
def forward(self, input):
return F.linear(input*self.mask, self.weight, self.bias)
And defining it like so:
net = nn.Sequential(nn.Linear(input_size, hidden_size),
LocalLinear(hidden_size, output_size))
CodePudding user response:
Instead of using nn.Linear directly, create a weights tensor weight and a mask tensor mask that masks those weights that you do not intend to use. Then you use torch.nn.functional.linear(input, weight * mask) (https://pytorch.org/docs/stable/generated/torch.nn.functional.linear.html) to forward the second layer. Note that this is implemented in your torch.nn.Module's forward function. The weight needs to be registered as a parameter to your nn.Module so that it's recognized by nn.Module.parameters(). See https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.register_parameter.