I m trying to write data into cosmos db using the dataframe df_u. i have defined the configureation in writeMcgMd. i m using spark version 3.2.1
Code -
df_u.write.format("cosmos.oltp").options(**writeMcgMd).mode("append").save()
Used -
writeMcgMd = {
"spark.cosmos.accountEndpoint" : "https://cccc.azure.com:443/",
"spark.cosmos.accountKey" : "ccc",
"spark.cosmos.database" : "cccc",
"spark.cosmos.container" : "ccc",
# "spark.cosmos.write.strategy": "ItemOverwrite"
}
Error from driver logs from databricks cluster [ Standard error] -
wnWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:565) at org.apache.spark.sql.execution.QueryExecution.$anonfun$eagerlyExecuteCommands$1(QueryExecution.scala:156) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:324) at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:156) at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:141) at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:132) at org.apache.spark.sql.execution.QueryExecution.assertCommandExecuted(QueryExecution.scala:186) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:956) at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:346) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:258) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380) at py4j.Gateway.invoke(Gateway.java:295) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:251) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 2 in stage 17.0 failed 4 times, most recent failure: Lost task 2.3 in stage 17.0 (TID 200) (10.240.26.5 executor 0): java.lang.IllegalArgumentException: requirement failed: id is a mandatory field. But it is missing or it is not a string. Json: {"_attachments":"attachments/","databasename":"mwhcicm","lastloadtime":"01-01-1900","parentname":"Mary","query":"SELECT x, y, z, a, \tLEFT(Text, 4000) as Text, Active,\tUpdateDate,\tInsertDate,\tRefNoteSubjectID,'x' as sourcedb,getdate() as processdate FROM o ","recordtype":"metadata","schema":"dbo","tableName":"o","where_col1":" WHERE UpdateDate > ","where_col2":" OR InsertDate > "} at scala.Predef$.require(Predef.scala:281) at com.azure.cosmos.spark.ItemsDataWriteFactory$CosmosWriter.write(ItemsDataWriteFactory.scala:106) at com.azure.cosmos.spark.ItemsDataWriteFactory$CosmosWriter.write(ItemsDataWriteFactory.scala:71) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$1(WriteToDataSourceV2Exec.scala:436) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1689) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:474) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.$anonfun$writeWithV2$2(WriteToDataSourceV2Exec.scala:375) at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$3(ResultTask.scala:75) at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110) at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$1(ResultTask.scala:75) at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:55) at org.apache.spark.scheduler.Task.doRunTask(Task.scala:156) at org.apache.spark.scheduler.Task.$anonfun$run$1(Task.scala:125) at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110) at org.apache.spark.scheduler.Task.run(Task.scala:95) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$13(Executor.scala:825) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1655) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:828) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:683) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Suppressed: java.lang.IllegalStateException: The Spark task was aborted, Context: SparkTaskContext(correlationActivityId=c27b3c5a-5038-4ce5-b1fa-9bb238917860,stageId=17,partitionId=2,taskAttemptId=200,details=) at com.azure.cosmos.spark.BulkWriter.abort(BulkWriter.scala:625) at com.azure.cosmos.spark.ItemsDataWriteFactory$CosmosWriter.abort(ItemsDataWriteFactory.scala:129) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$6(WriteToDataSourceV2Exec.scala:470) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1700) ... 20 more
Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2984) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2931) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2925) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2925) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1345) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1345) at scala.Option.foreach(Option.scala:407) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1345) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:3193) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3134) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3122) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:1107) at org.apache.spark.SparkContext.runJobInternal(SparkContext.scala:2637) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2620) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:371) ... 46 more Caused by: java.lang.IllegalArgumentException: requirement failed: id is a mandatory field. But it is missing or it is not a string. Json:
CodePudding user response:
java.lang.IllegalArgumentException: requirement failed: id is a mandatory field. But it is missing, or it is not a string.
This error indicates that the values you are passing to the JSON document being delivered to the service do not have the necessary ID field.
Because of this necessary attribute "id;" is absent, the input is showing invalid.
To overcome this, specify an id property with a string value as part of your document.
With this approach we reproduced the same scenario in our environment, and it worked.
Make sure you install CosmosDB-Spark connector library.
Below is the sample code,
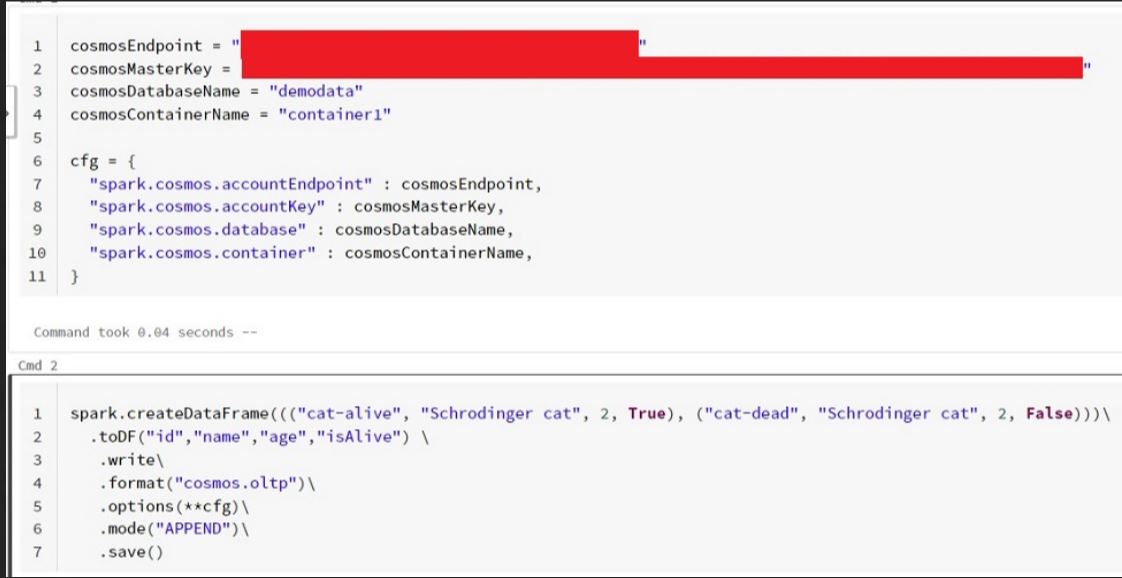
Output:
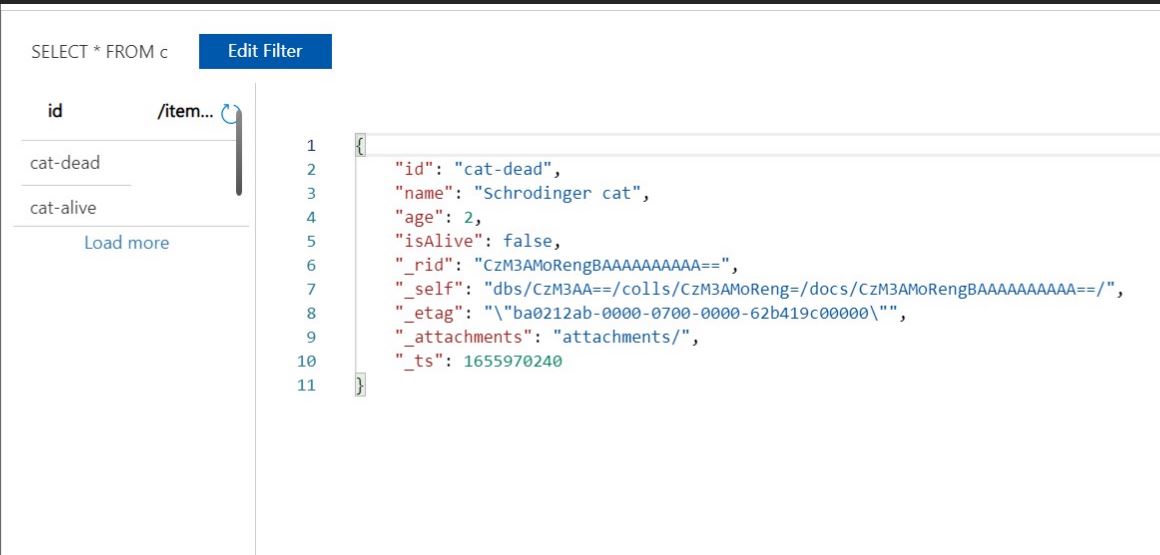
Reference of Missing the ID property.