My problem is that I can not convert this:
import pandas as pd
example = {
"ID": [1, 1, 2, 2, 2, 3],
"place":["Maryland","Maryland", "Washington", "Washington", "Washington", "Los Angeles"],
"sex":["male","male","female", "female", "female", "other"],
"depression": [0, 0, 0, 0, 0, 1],
"stressed": [1 ,0, 0, 0, 0, 0],
"sleep": [1, 1, 1, 0, 1, 1],
"ate":[0,1, 0, 1, 0, 1],
}
#load into df:
example = pd.DataFrame(example)
print(example)
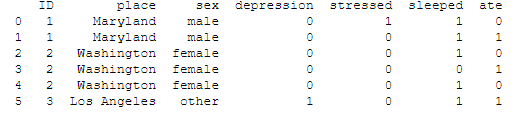
to this:
import pandas as pd
result = {
"ID": [1, 2, 3],
"place":["Maryland","Washington","Los Angeles"],
"sex":["male", "female", "other"],
"depression": [0, 0, 1],
"stressed": [1,0,0],
"sleep": [1, 1, 1],
"ate":[1, 1 , 1],
}
#load into df:
result = pd.DataFrame(result)
print(result)

I was trying to pivot it like this:
table = example.pivot_table(index='place',columns='ID')
print (table)
However, it looks totally different and I am confused how to set values for it. Could you please let me know what I am doing wrong.
Huge thanks in advance!
CodePudding user response:
I think you just want groupby with max (which acts as a logical OR on 1/0 values) as an aggregation function:
example.groupby(['ID', 'place','sex']).max().reset_index()
Output:
ID place sex depression stressed sleep ate
0 1 Maryland male 0 1 1 1
1 2 Washington female 0 0 1 1
2 3 Los Angeles other 1 0 1 1
CodePudding user response:
You can use groupby and any to get there:
example.groupby(['ID','place','sex']).any().astype(int).reset_index()
ID place sex depression stressed sleep ate
0 1 Maryland male 0 1 1 1
1 2 Washington female 0 0 1 1
2 3 Los Angeles other 1 0 1 1
CodePudding user response:
The default aggregation function is mean, to keep it binary, use aggfunc='max':
table = example.pivot_table(index='place', columns='ID', aggfunc=np.max, fill_value=0)
Output:
stressed
ID 1 2 3
place
Los Angeles 0 0 0
Maryland 1 0 0
Washington 0 0 0
Although in your case you might want a Groupby.max:
example.groupby(['ID', 'place', 'sex'], as_index=False).max()
Output:
ID place sex depression stressed sleep ate
0 1 Maryland male 0 1 1 1
1 2 Washington female 0 0 1 1
2 3 Los Angeles other 1 0 1 1