I'm having trouble creating a data frame to store my regression results. For each ticker, it calculates the coefficient(Beta) and its standard error with its respected window.
The new problem that I'm having is that the rows are repeating themselves to calculate each value per column resulting in NaN values. How can I correct the concat?
Here is the code
def rolling_regression_stats():
tickers = df[['FDX', 'BRK', 'MSFT', 'NVDA', 'INTC', 'AMD', 'JPM', 'T', 'AAPL', 'AMZN', 'GS']]
rolling_window = df
iterable = zip(range(1110), range(52,1162))
total_df = pd.DataFrame()
for y, x in iterable:
for t in tickers:
model = smf.ols(f'{t} ~ SP50', data= rolling_window.iloc[y:x]).fit()
beta_coef = model.params['SP50']
std_error = model.bse['SP50']
window_range = (f'{y}-{x}')
results = pd.DataFrame({
"Window":window_range,
f"{t} Beta":beta_coef,
f"{t}Beta STD": std_error,
},index=[0])
total_df = pd.concat([total_df,results], axis=0)
print(total_df)
rolling_regression_stats()
Here is the example of the dataframe I'm trying to create
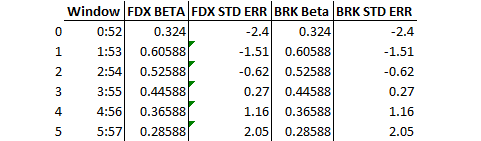
Here is the current output. But it seems that the calculations are skipping rows for each column resulting in Nan Values.
Window FDX Beta FDXBeta STD BRK Beta BRKBeta STD MSFT Beta MSFTBeta STD NVDA Beta ... T Beta TBeta STD AAPL Beta AAPLBeta STD AMZN Beta AMZNBeta STD GS Beta GSBeta STD
0 0-52 -0.288299 0.346499 NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
1 0-52 NaN NaN -0.396694 0.366258 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
2 0-52 NaN NaN NaN NaN 1.214212 0.527404 NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
3 0-52 NaN NaN NaN NaN NaN NaN 7.324437 ... NaN NaN NaN NaN NaN NaN NaN NaN
4 0-52 NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
12205 1109-1161 NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
12206 1109-1161 NaN NaN NaN NaN NaN NaN NaN ... -0.294726 0.043549 NaN NaN NaN NaN NaN NaN
12207 1109-1161 NaN NaN NaN NaN NaN NaN NaN ... NaN NaN 108.959035 12.653105 NaN NaN NaN NaN
12208 1109-1161 NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN 5.257065 2.785473 NaN NaN
12209 1109-1161 NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN 1.325418 0.244893
CodePudding user response:
Can you do something like this:
# create a storage df; store this outside of your loop
total_df = pd.DataFrame()
# create your dataframe with results for one regression in the loop
results = pd.DataFrame({
"Window":window_range,
f"{t} Beta":beta_coef,
f"{t}Beta STD": std_error,
},index=[0])
# concat the result in the loop like so
total_df = pd.concat([total_df, results], axis=0)
CodePudding user response:
Here is an example using the logic outlined in my comment above. You can see one dataframe (yx_df) is initialized for every new y, x values, then new columns are concatenated to it for different ticker values with yx_df = pd.concat([yx_df, res], axis = 1), and finally a full row is concatenated to the total_df after the loop over all tickers is done with total_df = pd.concat([total_df, yx_df], axis = 0, ignore_index=True).
Edit: Added window column to the initialization of the yx_df dataframe. That column only needs to have its value assigned once when new y, x values are obtained.
def rolling_reg():
tickers = ['FDX', 'BRK']
iterable = zip(range(5), range(50, 55))
total_df = pd.DataFrame()
for y, x in iterable:
yx_df = pd.DataFrame({'window': [f'{y}-{x}']})
for t in tickers:
res = pd.DataFrame(
{t: np.random.randint(0, 10), f"{t}_2": np.random.randn(1)}
)
yx_df = pd.concat([yx_df, res], axis = 1)
total_df = pd.concat([total_df, yx_df], axis = 0, ignore_index=True)
return total_df
rolling_reg()
# window FDX FDX_2 BRK BRK_2
# 0 0-50 7 0.232365 6 -1.491573
# 1 1-51 9 0.302536 1 0.871351
# 2 2-52 6 0.233803 9 -1.306058
# 3 3-53 7 -0.203941 8 0.454480
# 4 4-54 7 -0.618590 7 0.810528