Given a Pandas DF column that looks like this:
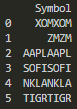
...how can I turn it into this:
XOM
ZM
AAPL
SOFI
NKLA
TIGR
Although these strings appear to be 4 characters in length maximum, I can't rely on that, I want to be able to have a string like ABCDEFGHIJABCDEFGHIJ and still be able to turn it into ABCDEFGHIJ in one column calculation. Preferably WITHOUT for looping/iterating through the rows.
CodePudding user response:
You can use regex pattern like r'\b(\w )\1\b' with str.extract like below:
df = pd.DataFrame({'Symbol':['ZOMZOM', 'ZMZM', 'SOFISOFI',
'ABCDEFGHIJABCDEFGHIJ', 'NOTDUPLICATED']})
print(df['Symbol'].str.extract(r'\b(\w )\1\b'))
Output:
0
0 ZOM
1 ZM
2 SOFI
3 ABCDEFGHIJ
4 NaN # <- from `NOTDUPLICATED`
Explanation:
\bis a word boundary(w )capture a word\1references to captured(w )of the first group
CodePudding user response:
An alternative approach which does involve iteration, but also regular expressions. Evaluate longest possible substrings first, getting progressively shorter. Use the substring to compile a regex that looks for the substring repeated two or more times. If it finds that, replace it with a single occurrence of the substring.
Does not handle leading or trailing characters. that are not part of the repetition.
When it performs a removal, it returns, breaking the loop. Going with longest substrings first ensures things like 'AAPLAAPL' leave the double A intact.
import re
def remove_repeated(str):
for i in range(len(str)):
substr = str[i:]
pattern = re.compile(f"({substr}){{2,}}")
if pattern.search(str):
return pattern.sub(substr, str)
return str
>>> remove_repeated('abcdabcd')
'abcd'
>>> remove_repeated('abcdabcdabcd')
'abcd'
>>> remove_repeated('aabcdaabcdaabcd')
'aabcd'
If we want to make this more flexible, a helper function to get all of the substrings in a string, starting with the longest, but as a generator expression so we don't have to actually generate more than we need.
def substrings(str):
return (str[i:i l] for l in range(len(str), 0, -1)
for i in range(len(str) - l 1))
>>> list(substrings("hello"))
['hello', 'hell', 'ello', 'hel', 'ell', 'llo', 'he', 'el', 'll', 'lo', 'h', 'e', 'l', 'l', 'o']
But there's no way 'hello' is going to be repeated in 'hello', so we can make this at least somewhat more efficient by looking at only substrings at most half the length of the input string.
def substrings(str):
return (str[i:i l] for l in range(len(str)//2, 0, -1)
for i in range(len(str) - l 1))
>>> list(substrings("hello"))
['he', 'el', 'll', 'lo', 'h', 'e', 'l', 'l', 'o']
Now, a little tweak to the original function:
def remove_repeated(str):
for s in substrings(str):
pattern = re.compile(f"({s}){{2,}}")
if pattern.search(str):
return pattern.sub(s, str)
return str
And now:
>>> remove_repeated('AAPLAAPL')
'AAPL'
>>> remove_repeated('fooAAPLAAPLbar')
'fooAAPLbar'