 Friends for me to finish my test and I just need to extract the text of the tooltip from the specific line of the table. Thomas Walpole has helped me a lot. Now I can read the excel spreadsheet and I will validate with each line of the application.
Friends for me to finish my test and I just need to extract the text of the tooltip from the specific line of the table. Thomas Walpole has helped me a lot. Now I can read the excel spreadsheet and I will validate with each line of the application.
****** I read excel and get the first line *************
Spreadsheet.client_encoding = 'UTF-8'
book = Spreadsheet.open('c:/temp/Pasta1.xls', "r")
sheet = book.worksheet 0
#sheet.each do |row|
pp hydrometer = sheet.row(1)
****** reading the specific row of the table *************
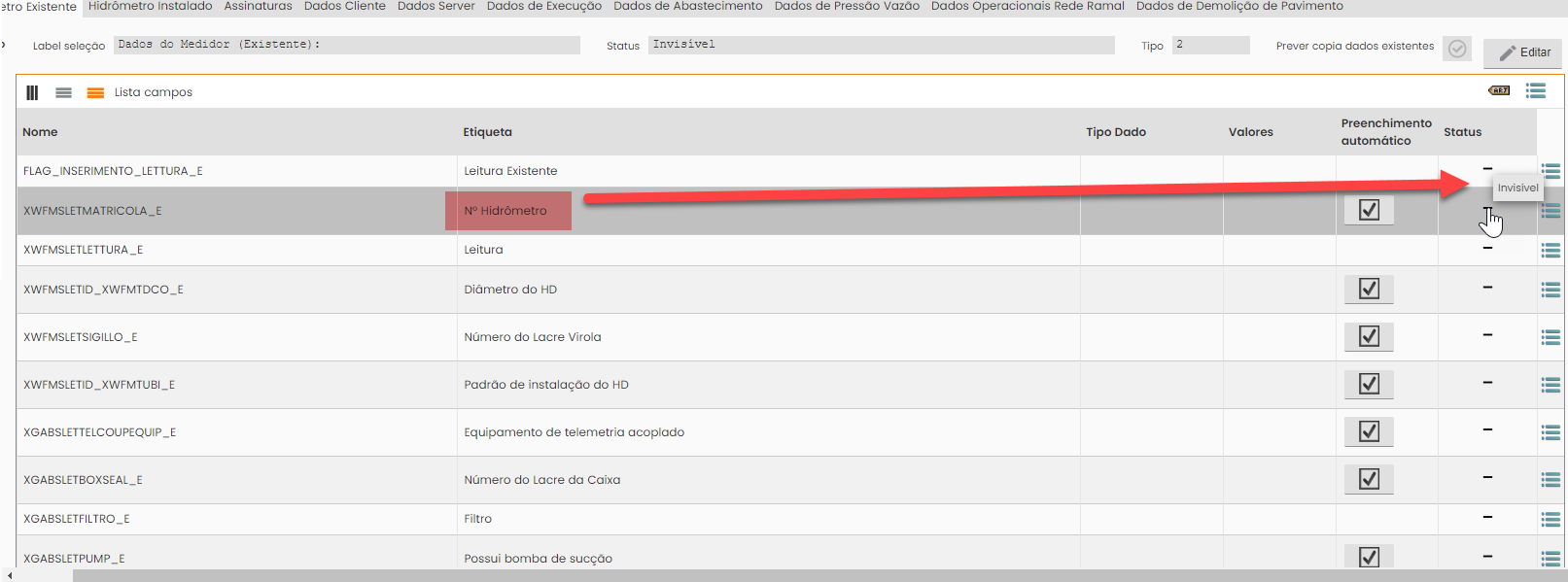
I just need to extract this text save in a variable and validate with the hydrometer variable that stores the row of my excel sheet
expect(page).to have_css('tr.tvRow:nth-child(2) .tvCell:nth-child(6) img[tooltip="Invisível"]')
CodePudding user response:
If hydrometer contains the text you're checking for just interpolate it in the CSS selector you're using
expect(page).to have_css("tr.tvRow:nth-child(2) .tvCell:nth-child(6) img[tooltip='#{hydrometer}']")
Since your going through a loop you'd probably also want to interpolate the row number but I don't know what variable you have that in
expect(page).to have_css("tr.tvRow:nth-child(#{row_number}) .tvCell:nth-child(6) img[tooltip='#{hydrometer}']")
If you really want to get the tooltip text for a specific row you would do
text = find("tr.tvRow:nth-child(2) .tvCell:nth-child(6) img[tooltip]")[:tooltip] # get the tooltip attribute value from the 2nd row
but doing that and then comparing it to some other string is bad practice and will lead to flaky tests. It is much better to do the have_css shown above