I’m happy with the equation although wanted to make a tweak, just unsure how to achieve what I’m after… The equation is the following and it gives the result of the following table: =(COUNTIFS($B$3:B3,B3,$Z$3:Z3,0)=0)*(COUNTIFS(B:B,B3,U:U,U3<>"",Z:Z,0)=0)
| B (projectID) | U(Project phase/stage) | Z(success=1,non-successful=0 | My new column |
|---|---|---|---|
| 2 | 1 | 1 | 0 |
| 2 | 1 | 0 | 0 |
| 2 | 2 | 0 | 0 |
| 3 | 1 | 1 | 1 |
| 3 | 2 | 0 | 0 |
| 4 | 1 | 0 | 0 |
| 4 | 2 | 1 | 0 |
| 4 | 3 | 0 | 0 |
| 4 | 4 | 1 | 0 |
| 4 | 5 | 1 | 0 |
| 4 | 5 | 0 | 0 |
| 5 | 1 | 1 0 | |
| 5 | 1 | 0 | 0 |
| 5 | 1 | 0 | 0 |
| 5 | 2 | 1 | 0 |
| 5 | 2 | 0 | 0 |
| 5 | 2 | 0 | 0 |
| 5 | 3 | 0 | 0 |
| 5 | 3 | 1 | 0 |
| 5 | 3 | 0 | 0 |
B: projectID U: phase of project Z: success/not for individual projects (0=unsuccessful; or 1 = successful) new column: success/not for individual projects (taking into account phase of project)
I would like to change it so that it has all the same rules as the above, however if for the same projectID (Column B) and same phase (COLUMN u) and if the FIRST number (column Z) has a value of 0, all the rest of the duplicated values, all values with the same Column B and Column U are the same… Unless: there is a phase before that (with the same projectID) that has a resulting column Z value of 0. This is already incorporated into the equation above
| B | U | Z | My new column |
|---|---|---|---|
| 2 | 1 | 1 | 1 |
| 2 | 1 | 0 | 1 |
| 2 | 2 | 0 | 0 |
| 3 | 1 | 1 | 1 |
| 3 | 2 | 0 | 0 |
| 4 | 1 | 0 | 0 |
| 4 | 2 | 1 | 0 |
| 4 | 3 | 0 | 0 |
| 4 | 4 | 1 | 0 |
| 4 | 5 | 1 | 0 |
| 4 | 5 | 0 | 0 |
| 5 | 1 | 1 | 1 |
| 5 | 1 | 0 | 1 |
| 5 | 1 | 0 | 1 |
| 5 | 2 | 1 | 1 |
| 5 | 2 | 0 | 1 |
| 5 | 2 | 0 | 1 |
| 5 | 3 | 0 | 0 |
| 5 | 3 | 1 | 0 |
| 5 | 3 | 0 | 0 |
| 6 | 0 | 0 | |
| 6 | 1 | 0 | |
| 6 | 0 | 0 | |
| 7 | 1 | 1 | |
| 7 | 1 | 1 | |
| 7 | 0 | 1 |
Any recommendations would be wonderful!!! Thanks
CodePudding user response:
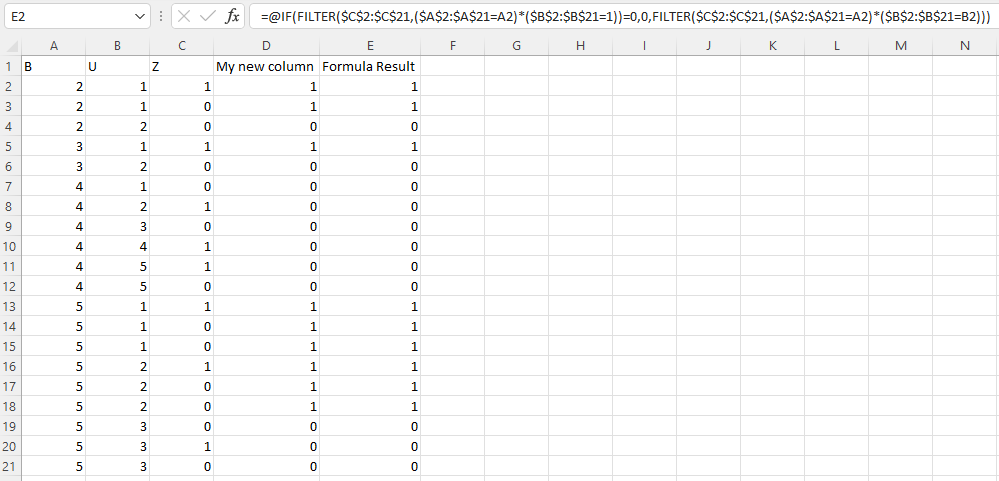
Try below FILTER() formula-
=@IF(FILTER($C$2:$C$21,($A$2:$A$21=A2)*($B$2:$B$21=1))=0,0,FILTER($C$2:$C$21,($A$2:$A$21=A2)*($B$2:$B$21=B2)))