We have a simple input file as in the picture. We load the csv input into pandas dataframe, and we want to rename the first n-th columns, in this example, the first three columns.
The code
import pandas as pd
file_path = r"C:\Codes\test\test_data.csv"
df1 = pd.read_csv(file_path)
print (df1, "\n", type(df1), "\n", df1.columns, "\n", type(df1.columns), "\n", df1.columns.values, "\n", type(df1.columns.values))
df2 = df1.copy()
print (df2, "\n", type(df2), "\n", df2.columns, "\n", type(df2.columns), "\n", df2.columns.values, "\n", type(df2.columns.values))
df2.columns.values[0:3] = ["symbol","field","abc"]
print("\n after renaming the columns: ", df2)
print(df2["symbol"])
The result is as follows:
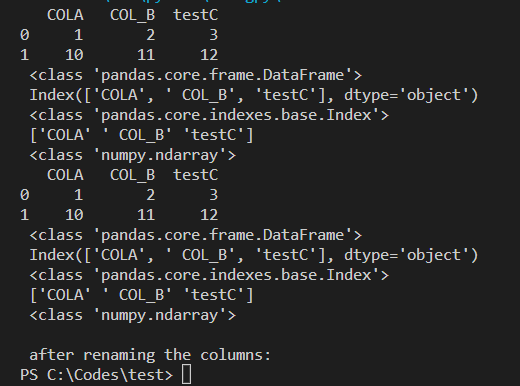
It seems that the code df2.columns.values[0:3] = ["symbol","field","abc"] is not stable. Sometimes it works and sometimes it does not, for example, it may report an "KeyError" or the code freeze when trying to display df2. I do understand why it does not work.
I am working on Windows 10, with Python 3.10.4
Of course, I can also write the following code, which works
df2.rename(columns={df2.columns[0]: "symbol"},inplace=True)
df2.rename(columns={df2.columns[1]: "field"},inplace=True)
df2.rename(columns={df2.columns[2]: "abc"},inplace=True)
But my goal is to change the first n-th columns in a simple code.
CodePudding user response:
You can try updating the column labels like this:
df2 = df2.rename(columns=dict(zip(list(df2.columns)[0:3], ["symbol","field","abc"])))
... or like this:
df2.columns = ["symbol","field","abc"] list(df2.columns)[3:]
Output:
COLA COL_B testC
0 1 2 3
1 10 11 12
<class 'pandas.core.frame.DataFrame'>
Index(['COLA', 'COL_B', 'testC'], dtype='object')
<class 'pandas.core.indexes.base.Index'>
['COLA' 'COL_B' 'testC']
<class 'numpy.ndarray'>
COLA COL_B testC
0 1 2 3
1 10 11 12
<class 'pandas.core.frame.DataFrame'>
Index(['COLA', 'COL_B', 'testC'], dtype='object')
<class 'pandas.core.indexes.base.Index'>
['COLA' 'COL_B' 'testC']
<class 'numpy.ndarray'>
after renaming the columns:
symbol field abc
0 1 2 3
1 10 11 12
df2["symbol"]
0 1
1 10
Name: symbol, dtype: int64
Note that the docs for Index.values have a warning which reads:
We recommend using Index.array or Index.to_numpy(), depending on whether you need a reference to the underlying data or a NumPy array.