My data is as follows (this is just a sample, real data has ~20,000 lines) :
Original raw data (tsv):
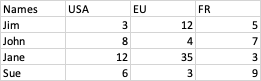
Names USA EU FR
Jim 3 12 5
John 8 4 7
Jane 12 35 3
Sue 6 3 9
Image of original Data:
I want to loop over each col starting with col 2 and if values are greater than 5, then print the column 1 value of that line. The resulting data should be as follows (tab separated):
Resulting Raw Data (tsv):
USA EU FR
John Jim John
Jane Jane Sue
Sue
Image of resulting data:

I have tried the following:
awk -F"\t" '{
for(i=2; i<=NF; i ) {
if($i > 5){
print $1
}
}
}' file > results
But it prints all the results in a single column and doesnt grab the headers of the other cols. I have also tried to capture the header during each loop step with print FNR == i {print $1} "\n" but I get a syntax error related to the index:
awk: cmd. line:4: print FNR == i {print $1} "\n"
awk: cmd. line:4: ^ syntax error
awk: cmd. line:8: }
awk: cmd. line:8: ^ syntax error
CodePudding user response:
The expected output you provided doesn't show what you describe as your requirements so maybe this is what you really want:
$ cat tst.awk
BEGIN { FS=OFS="\t" }
NR > 1 {
for ( i=2; i<=NF; i ) {
$i = ( $i > 5 ? $1 : "" )
}
}
{
$1 = ""
sub(OFS,"")
print
}
$ awk -f tst.awk file
USA EU FR
Jim
John John
Jane Jane
Sue Sue
CodePudding user response:
One GNU awk (for multidimensional arrays) idea:
awk '
BEGIN { FS=OFS="\t" }
NR==1 { for (col=2;col<=NF;col )
output=output (col==2 ? "" : OFS) $col
print output
next
}
{ for (col=2;col<=NF;col )
if ($col > 5)
names[ count[col]][col]=$1
}
END { for (col=2;col<=NF;col )
maxlines=(count[col]>maxlines ? count[col] : maxlines)
for (lineno=1;lineno<=maxlines;lineno ) {
output=""
for (col=2;col<=NF;col )
output=output (col==2 ? "" : OFS) names[lineno][col]
print output
}
}
' file.tsv
This generates:
USA EU FR
John Jim John
Jane Jane Sue
Sue