I'm trying to find out how to use Mojo::DOM with UTF8 (and other formats... not just UTF8). It seems to mess up the encoding:
my $dom = Mojo::DOM->new($html);
$dom->find('script')->reverse->each(sub {
#print "$_->{id}\n";
$_->remove;
});
$dom->find('style')->reverse->each(sub {
#print "$_->{id}\n";
$_->remove;
});
$dom->find('script')->reverse->each(sub {
#print "$_->{id}\n";
$_->remove;
});
my $html = "$dom"; # pass back to $html, now we have cleaned it up...
This is what I get when saving the file without running it through Mojo:
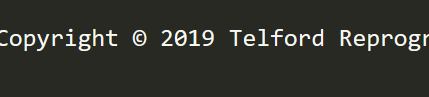
...and then once through Mojo:
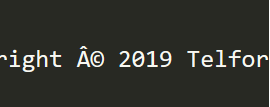
FWIW, I'm grabbing the HTML file using Path::Tiny, with:
my $utf8 = path($_[0])->slurp_raw;
Which to my understanding, should already have the string decoded into bytes ready for Mojo?
UPDATE: After Brians suggestion, I looked into how I could figure out the encoding type to decode it correctly. I tried Encode::Guess and a few others, but they seemed to get it wrong on quite a few. This one seems to do the trick:
my $enc_tmp = `encguess $_[0]`;
my ($fname,$type) = split /\s /, $enc_tmp;
my $decoded = decode( $type||"UTF-8", path($_[0])->slurp_raw );
CodePudding user response:
You are slurping raw octets but not decoding them (storing the raw in $utf8). Then you treat it as if you had decoded it, so the result is mojibake.
- If you read raw octets, decode it before you use it. You'll end up with the right Perl internal string.
slurp_utf8will decode for you.- Likewise, you have to encode when you output again. The
openpragma does that in this example. - Mojolicious already has
Mojo::File->slurpto get raw octets, so you can reduce your dependency list.
use v5.10;
use utf8;
use open qw(:std :utf8);
use Path::Tiny;
use Mojo::File;
use Mojo::Util qw(decode);
my $filename = 'test.txt';
open my $fh, '>:encoding(UTF-8)', $filename;
say { $fh } "Copyright © 2022";
close $fh;
my $octets = path($filename)->slurp_utf8;
say "===== Path::Tiny::slurp_raw, no decode";
say path($filename)->slurp_raw;
say "===== Path::Tiny::slurp_raw, decode";
say decode( 'UTF-8', path($filename)->slurp_raw );
say "===== Path::Tiny::slurp_utf8";
say path($filename)->slurp_utf8;
say "===== Mojo::File::slurp, decode";
say decode( 'UTF-8', Mojo::File->new($filename)->slurp );
The output:
===== Path::Tiny::slurp_raw, no decode
Copyright © 2022
===== Path::Tiny::slurp_raw, decode
Copyright © 2022
===== Path::Tiny::slurp_utf8
Copyright © 2022
===== Mojo::File::slurp, decode
Copyright © 2022