I'm new to Spark and I tried some transformations on data frames. I have a data frame that look likes this (one column named "value" with a json string in it). I sent it to an Event Hub using Kafka API and then I want to read that data from the Event Hub and apply some transformations to it. The data is in received in binary format, as described in the Kafka documentation.
Here are a few columns in csv format:
value
"{""id"":""e52f247c-f46c-4021-bc62-e28e56db1ad8"",""latitude"":""34.5016064725731"",""longitude"":""123.43996453687777""}"
"{""id"":""32782100-9b59-49c7-9d56-bb4dfc368a86"",""latitude"":""49.938541626415144"",""longitude"":""111.88360885971986""}"
"{""id"":""a72a600f-2b99-4c41-a388-9a24c00545c0"",""latitude"":""4.988768300413497"",""longitude"":""-141.92727675177588""}"
"{""id"":""5a5f056a-cdfd-4957-8e84-4d5271253509"",""latitude"":""41.802942545247134"",""longitude"":""90.45164573613573""}"
"{""id"":""d00d0926-46eb-45dd-9e35-ab765804340d"",""latitude"":""70.60161063520081"",""longitude"":""20.566520665122482""}"
"{""id"":""dda14397-6922-4bb6-9be3-a1546f08169d"",""latitude"":""68.400462882435"",""longitude"":""135.7167027587489""}"
"{""id"":""c7f13b8a-3468-4bc6-9db4-e0b1b34bf9ea"",""latitude"":""26.04757722355835"",""longitude"":""175.20227554031783""}"
"{""id"":""97f8f1cf-3aa0-49bb-b3d5-05b736e0c883"",""latitude"":""35.52624182094499"",""longitude"":""-164.18066699972852""}"
"{""id"":""6bed49bc-ee93-4ed9-893f-4f51c7b7f703"",""latitude"":""-24.319581484353847"",""longitude"":""85.27338980948076""}"
What I want to do is to apply a transformation and create a data frame with 3 columns one with id, one with latitude and one with longitude. This is what I tried but the result is not what I expected:
from pyspark.sql.types import StructType
from pyspark.sql.functions import from_json
from pyspark.sql import functions as F
#df is the data frame received from Kafka
location_schema = StructType().add("id", "string").add("latitude", "float").add("longitude", "float")
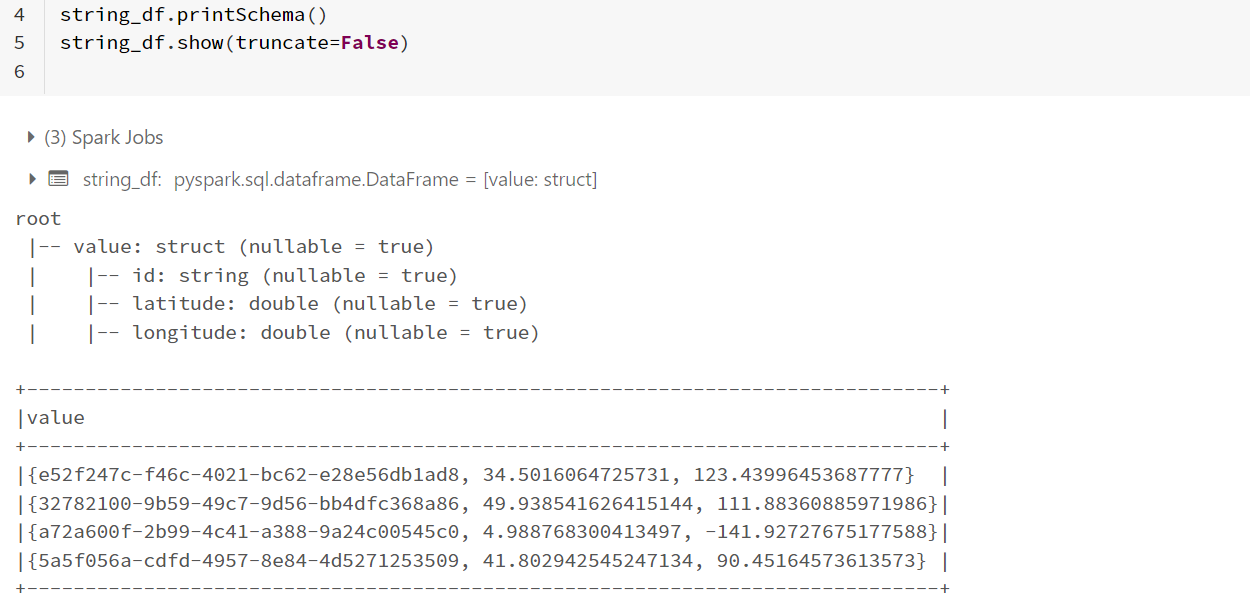
string_df = df.selectExpr("CAST(value AS STRING)").withColumn("value", from_json(F.col("value"), location_schema))
string_df.printSchema()
string_df.show()
And this is the result:
It created a "value" column with a structure as a value. Any idea what to do to obtain 3 different columns, as I described. Thank you!
CodePudding user response:
Your df:
df = spark.createDataFrame(
[
(1, '{"id":"e52f247c-f46c-4021-bc62-e28e56db1ad8","latitude":"34.5016064725731","longitude":"123.43996453687777"}'),
(2, '{"id":"32782100-9b59-49c7-9d56-bb4dfc368a86","latitude":"49.938541626415144","longitude":"111.88360885971986"}'),
(3, '{"id":"a72a600f-2b99-4c41-a388-9a24c00545c0","latitude":"4.988768300413497","longitude":"-141.92727675177588"}'),
(4, '{"id":"5a5f056a-cdfd-4957-8e84-4d5271253509","latitude":"41.802942545247134","longitude":"90.45164573613573"}'),
(5, '{"id":"d00d0926-46eb-45dd-9e35-ab765804340d","latitude":"70.60161063520081","longitude":"20.566520665122482"}'),
(6, '{"id":"dda14397-6922-4bb6-9be3-a1546f08169d","latitude":"68.400462882435","longitude":"135.7167027587489"}'),
(7, '{"id":"c7f13b8a-3468-4bc6-9db4-e0b1b34bf9ea","latitude":"26.04757722355835","longitude":"175.20227554031783"}'),
(8, '{"id":"97f8f1cf-3aa0-49bb-b3d5-05b736e0c883","latitude":"35.52624182094499","longitude":"-164.18066699972852"}'),
(9, '{"id":"6bed49bc-ee93-4ed9-893f-4f51c7b7f703","latitude":"-24.319581484353847","longitude":"85.27338980948076"}')
],
['id', 'value']
).drop('id')
--------------------------------------------------------------------------------------------------------------
|value |
--------------------------------------------------------------------------------------------------------------
|{"id":"e52f247c-f46c-4021-bc62-e28e56db1ad8","latitude":"34.5016064725731","longitude":"123.43996453687777"} |
|{"id":"32782100-9b59-49c7-9d56-bb4dfc368a86","latitude":"49.938541626415144","longitude":"111.88360885971986"}|
|{"id":"a72a600f-2b99-4c41-a388-9a24c00545c0","latitude":"4.988768300413497","longitude":"-141.92727675177588"}|
|{"id":"5a5f056a-cdfd-4957-8e84-4d5271253509","latitude":"41.802942545247134","longitude":"90.45164573613573"} |
|{"id":"d00d0926-46eb-45dd-9e35-ab765804340d","latitude":"70.60161063520081","longitude":"20.566520665122482"} |
|{"id":"dda14397-6922-4bb6-9be3-a1546f08169d","latitude":"68.400462882435","longitude":"135.7167027587489"} |
|{"id":"c7f13b8a-3468-4bc6-9db4-e0b1b34bf9ea","latitude":"26.04757722355835","longitude":"175.20227554031783"} |
|{"id":"97f8f1cf-3aa0-49bb-b3d5-05b736e0c883","latitude":"35.52624182094499","longitude":"-164.18066699972852"}|
|{"id":"6bed49bc-ee93-4ed9-893f-4f51c7b7f703","latitude":"-24.319581484353847","longitude":"85.27338980948076"}|
--------------------------------------------------------------------------------------------------------------
Then:
from pyspark.sql import functions as F
from pyspark.sql.types import *
json_schema = StructType([
StructField("id", StringType(), True),
StructField("latitude", FloatType(), True),
StructField("longitude", FloatType(), True)
])
df\
.withColumn('json', F.from_json(F.col('value'), json_schema))\
.select(F.col('json').getItem('id').alias('id'),
F.col('json').getItem('latitude').alias('latitude'),
F.col('json').getItem('longitude').alias('longitude')
)\
.show(truncate=False)
------------------------------------ ------------------- -------------------
|id |latitude |longitude |
------------------------------------ ------------------- -------------------
|e52f247c-f46c-4021-bc62-e28e56db1ad8|34.5016064725731 |123.43996453687777 |
|32782100-9b59-49c7-9d56-bb4dfc368a86|49.938541626415144 |111.88360885971986 |
|a72a600f-2b99-4c41-a388-9a24c00545c0|4.988768300413497 |-141.92727675177588|
|5a5f056a-cdfd-4957-8e84-4d5271253509|41.802942545247134 |90.45164573613573 |
|d00d0926-46eb-45dd-9e35-ab765804340d|70.60161063520081 |20.566520665122482 |
|dda14397-6922-4bb6-9be3-a1546f08169d|68.400462882435 |135.7167027587489 |
|c7f13b8a-3468-4bc6-9db4-e0b1b34bf9ea|26.04757722355835 |175.20227554031783 |
|97f8f1cf-3aa0-49bb-b3d5-05b736e0c883|35.52624182094499 |-164.18066699972852|
|6bed49bc-ee93-4ed9-893f-4f51c7b7f703|-24.319581484353847|85.27338980948076 |
------------------------------------ ------------------- -------------------
CodePudding user response:
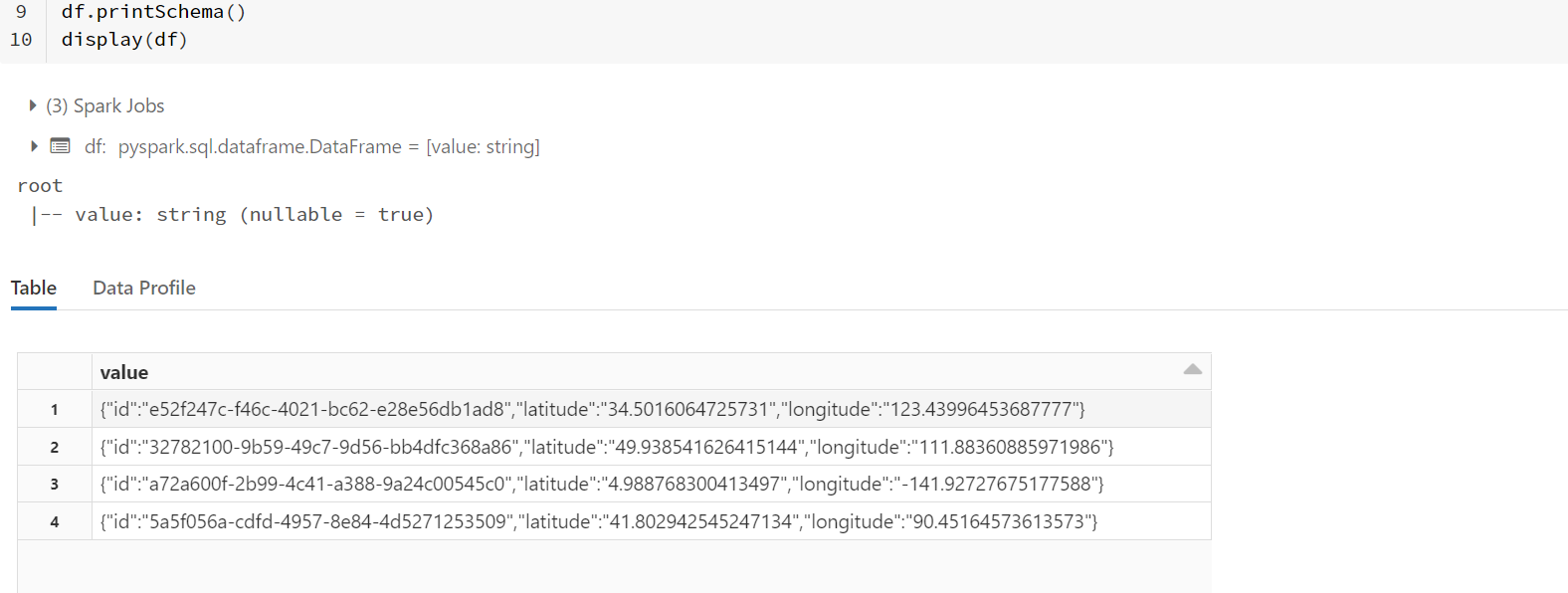
I used the sample data provided, created a dataframe called df and proceeded to use the same method as you.
- The following is the image of the rows present inside
dfdataframe.
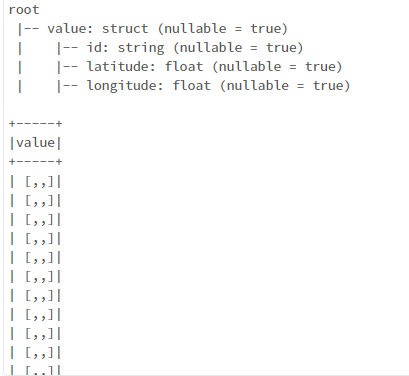
- The fields are not displayed as required because of the their datatype. The values for
latitudeandlongitudeare present asstringtypes in the dataframedf. But while creating the schemalocation_schemayou have specified their type asfloat. Instead, try changing their type tostringand later convert them todouble type. The code looks as shown below:
location_schema = StructType().add("id", "string").add("latitude", "string").add("longitude", "string")
string_df = df.selectExpr('CAST(value AS STRING)').withColumn("value", from_json(F.col("value"), location_schema))
string_df.printSchema()
string_df.show(truncate=False)
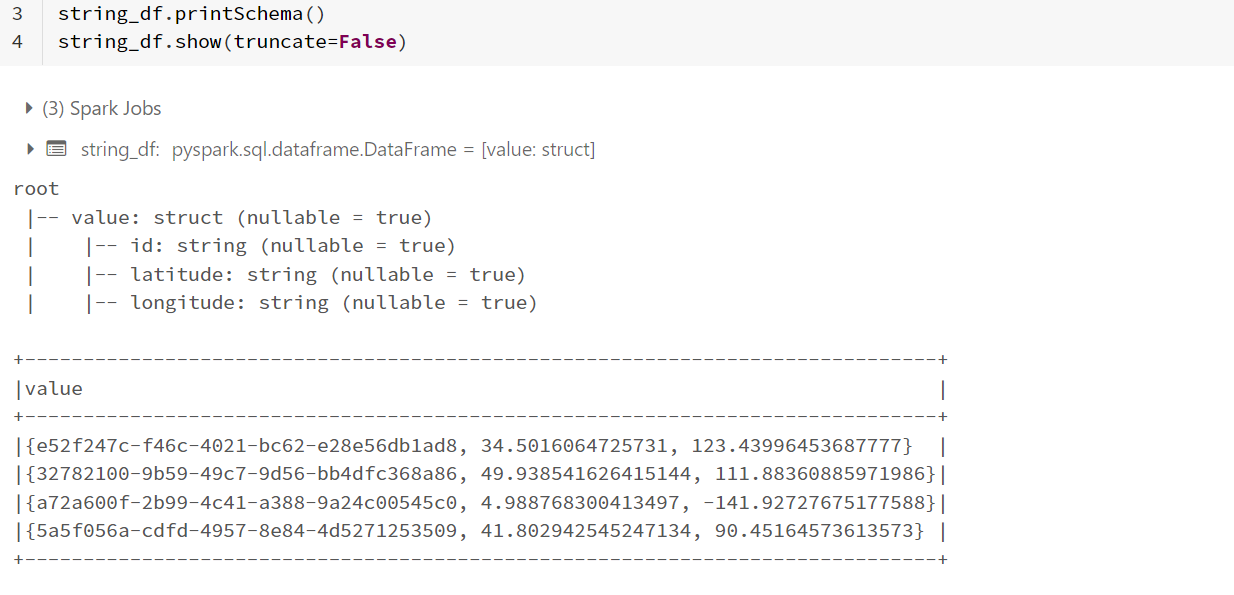
- Now using
DataFrame.withColumn(), Column.withField() and cast()convert the string type fields latitude and longitude toDouble Type.
string_df = string_df.withColumn("value", col("value").withField("latitude", col("value.latitude").cast(DoubleType())))\
.withColumn("value", col("value").withField("longitude", col("value.longitude").cast(DoubleType())))
string_df.printSchema()
string_df.show(truncate=False)
- So, you can get the desired output as shown below.