I am scraping this product page: 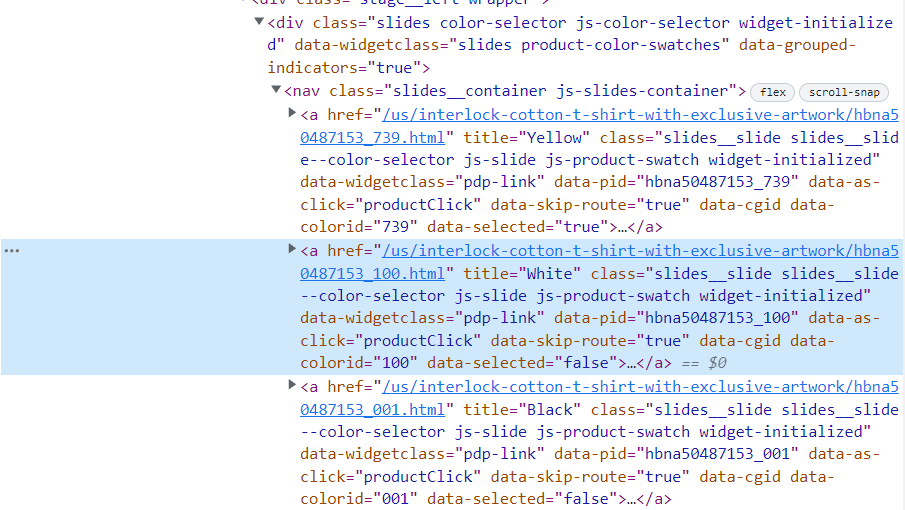
Current code:
import numpy as np
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup as soup
from selenium import webdriver
import time
import requests
driverfile = r'C:\Users\Main\Documents\Work\Projects\Scraping Websites\extra\chromedriver'
#driver.implicitly_wait(10)
url = "https://www.hugoboss.com/us/interlock-cotton-t-shirt-with-exclusive-artwork/hbna50487153_739.html"
def make_soup(url):
page = requests.get(url)
page_soup = soup(page.content, 'lxml')
return page_soup
product_page_soup = make_soup(url)
print(product_page_soup.select('a.slides__slide slides__slide--color-selector.js-slide.js-
product-swatch.widget-initialized'))
`
Current output: is an empty list []
Expected Output: HTML of the a tag
FYI: Selecting another A tag on the same product page works e.g: print(product_page_soup.select('a.dch-links-item.dch-links-item--released.dch-links-item--unstyled-selector.dch-links-item--bold--underscore.dch-links-item-tracking')[0].text.strip()) : This outputs desired text using the same method so I am confused why it would not work for a tag in question 'a.slides__slide slides__slide--color-selector.js-slide.js- product-swatch.widget-initialized'
I also tried using product_page_soup.findAll ('a', {"class":'slides__slide.slides__slide--color-selector.js-slide.js-product-swatch.widget-initialized'}) but got the same empty list
CodePudding user response:
The following CSS expression with bs4 will grab the desired links
[] div nav a')
Full working code:
import time
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get('https://www.hugoboss.com/us/interlock-cotton-t-shirt-with-exclusive-artwork/hbna50487153_739.html')
driver.maximize_window()
time.sleep(5)
soup = BeautifulSoup(driver.page_source, 'html.parser')
for u in soup.select('[] div nav a'):
link = 'https://www.hugoboss.com' u.get('href')
print(link)
Output:
https://www.hugoboss.com/us/interlock-cotton-t-shirt-with-exclusive-artwork/hbna50487153_739.html
https://www.hugoboss.com/us/interlock-cotton-t-shirt-with-exclusive-artwork/hbna50487153_100.html
https://www.hugoboss.com/us/interlock-cotton-t-shirt-with-exclusive-artwork/hbna50487153_001.html
CodePudding user response:
In page source link has @class "widget". I guess it replaced with "widget-initialized" after page rendered. So try
.widget
instead of
.widget-initialized
And so complete selector should be
a.slides__slide.slides__slide--color-selector.js-slide.js-product-swatch.widget
Also for better readability I would recommend to use CSS selector
'nav > a[data-as-click="productClick"]'