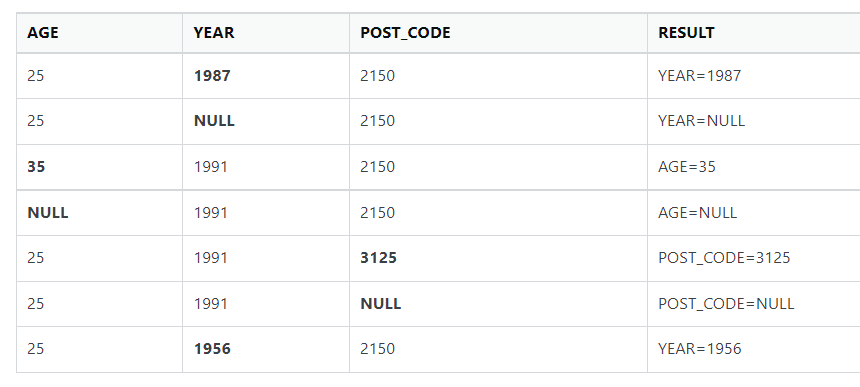
I have the below pandas dataframe where I would like derive an output into a column named "RESULT" based on the other values in the column across of the table
CodePudding user response:
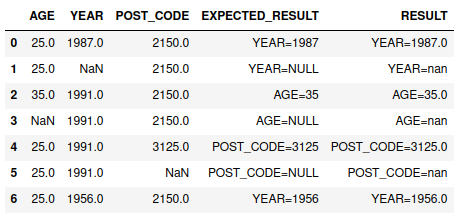
It needs a bit of beautification, but you can achieve it with apply on axis=1 and a for loop over the columns that you want to check.
df = pd.DataFrame({
'AGE': [25, 25, 35, np.nan, 25, 25, 25],
'YEAR': [1987, np.nan, 1991, 1991, 1991, 1991, 1956],
'POST_CODE': [2150, 2150, 2150, 2150, 3125, np.nan, 2150],
'EXPECTED_RESULT': ['YEAR=1987', 'YEAR=NULL', 'AGE=35', 'AGE=NULL', 'POST_CODE=3125', 'POST_CODE=NULL', 'YEAR=1956']
})
def custom_func(x: pd.Series, val_counts):
return f'{x.index[0]}={x[0]}' if val_counts[x[0]] == 1 and pd.isna(x[1]) else x[1]
cols = df.columns[:-1]
df['RESULT'] = np.nan
for col in cols:
val_counts = df.value_counts(col, dropna=False)
df['RESULT'] = df[[col, 'RESULT']].apply(lambda x: custom_func(x, val_counts), axis=1)
CodePudding user response:
You can try looping through the columns and use Series.duplicated to find the unique value
df['result'] = ''
for col in ['AGE', 'YEAR', 'POST_CODE']:
m = ~df[col].duplicated(keep=False)
df['result'] = df['result'].mask(m, col '=' df[col].astype(str))
print(df)
AGE YEAR POST_CODE result
0 25 1987 2150 YEAR=1987
1 25 NULL 2150 YEAR=NULL
2 35 1991 2150 AGE=35
3 NULL 1991 2150 AGE=NULL
4 25 1991 3125 POST_CODE=3125
5 25 1991 NULL POST_CODE=NULL
6 25 1956 2150 YEAR=1956