Question
Is it possible to groupby a range of numbers (int) in Pandas as per example below? If not, how would I achieve the desired output?
Data
df = pd.DataFrame(
{"price": [9, 8, 9, 10, 11, 6, 7, 8, 9, 9, 9, 9, 10, 11, 5]},
index=pd.date_range("19/3/2020", periods=15, freq="H"),
)
df["higher"] = np.where(df.price > df.price.shift(), 1, 0)
df["higher_count"] = df["higher"] * (
df["higher"].groupby((df["higher"] != df["higher"].shift()).cumsum()).cumcount() 1
)
df = df.drop("higher", axis=1)
Dataframe with the first group highlighted
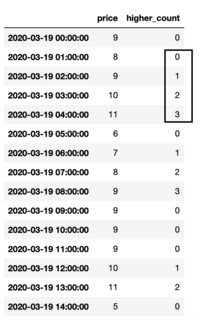
The groups can be extracted as follows:
from operator import itemgetter
from itertools import groupby
data = df["higher_count"]
for key, group in groupby(enumerate(data), lambda i: i[0] - i[1]):
group = list(map(itemgetter(1), group))
if len(group) > 1:
print(f"{key}:{group}")
1:[0, 1, 2, 3]
5:[0, 1, 2, 3]
11:[0, 1, 2]
Desired output
For each group generate the following columns:
- start date
- price at start date
- end date
- price at end date
so for the group with key 1 the output would be as follows:

CodePudding user response:
IIUC you can use diff and cumsum to group, then check if the group has more than 1 element:
df["group"] = df["higher_count"].diff().ne(1).cumsum()
print (df.loc[df.groupby("group")["higher_count"].transform(len)>1]
.rename_axis("date")
.reset_index()
.groupby("group")[["date", "price"]].agg(["first", "last"]))
date price
first last first last
group
2 2020-03-19 01:00:00 2020-03-19 04:00:00 8 11
3 2020-03-19 05:00:00 2020-03-19 08:00:00 6 9
6 2020-03-19 11:00:00 2020-03-19 13:00:00 9 11