I am trying to compute a rolling semivariance or semi std in a pandas series.
It all comes down to adding a condition, that replaces all values in the rolling window with NaN and then computing the standard deviation / variance in that window (or just filter out the values in the window).
So what I am looking for is something like this:
x = stock_prices.pct_change()
window = 10
rol_mean = x.rolling(window).mean()
sem_std = x.rolling(window)[x.rolling(window)<rol_mean].std()
But of course this throws an error as 'Series' object has no attribute 'columns' and '>' not supported between instances of 'float' and 'Rolling'.
pseudocode:
rol_sem_std = x.rolling(window=10).std() where < x.rolling(window=10).mean()
Thank you in advance for your help!
CodePudding user response:
If you know, given a series, how to compute the semi std - then you use .rolling().apply() with that function.
Using the definition from 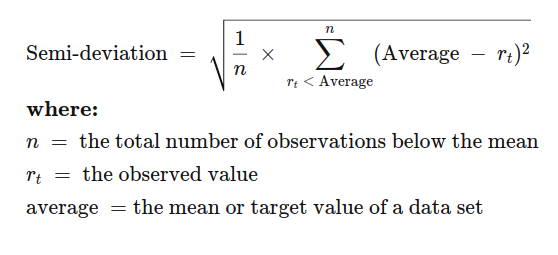
We cannot use the built-in std because we need to use the whole group average, but only compute deviations based on those observations in the group that are below the average.
Looks like we'll need to define the semi-deviation as a function:
import numpy as np
def semi_std(ser):
average = np.nanmean(ser)
r_below = ser[ser < average]
return np.sqrt(1/len(r_below) * np.sum((average - r_below)**2))
x.rolling(window).apply(semi_std, raw=True)
# using raw=True speeds up the computation - this is applicable
# if the function works well with a numpy array instead of a Series
# also, if possible, investigate using numba.
I think for maximum robustness, probably add a condition that if len(r_below) == 0 then the result is 0 or NaN (it's a matter of definition - but 0 is probably the reasonable choice).
CodePudding user response:
The solution is actually pretty simple if one knows how rolling windows work in Pandas. The trick here is to use the shift function on the dataframe first which shifts each row by one position so it becomes the last element of the previous row. Then we can do our rolling mean calculation without having any issues with type conversion etc.
import pandas as pd
from datetime import timedelta
df = pd.DataFrame(data=np.random.randn(5, 4), index=pd.date_range('1/1/2000', periods=5))
df.index = df.index timedelta(days=10)
print(df)
CodePudding user response:
Found a solution using this previous thread: How to create a rolling window in pandas with another condition
N = 10
# End slice ensures same default min_periods behavior to `.rolling`
df1 = pd.concat([x.shift(i).rename(i) for i in range(N)], axis=1).iloc[:]
# Remove values larger than B, then find the max of remaining.
df = df1.where(df1.lt(rol_mean, axis=0)).std(1)