P = np.array(
[
[0.03607908, 0.03760034, 0.00503184, 0.0205082 , 0.01051408,
0.03776221, 0.00131325, 0.03760817, 0.01770659],
[0.03750162, 0.04317351, 0.03869997, 0.03069872, 0.02176718,
0.04778769, 0.01021053, 0.00324185, 0.02475319],
[0.03770951, 0.01053285, 0.01227089, 0.0339596 , 0.02296711,
0.02187814, 0.01925662, 0.0196836 , 0.01996279],
[0.02845139, 0.01209429, 0.02450163, 0.00874645, 0.03612603,
0.02352593, 0.00300314, 0.00103487, 0.04071951],
[0.00940187, 0.04633153, 0.01094094, 0.00172007, 0.00092633,
0.02032679, 0.02536328, 0.03552956, 0.01107725]
]
)
Here's the dataset where X corresponds to rows and Y corresponds to columns. I'm trying to figure out how to calculate the Covariance and Marginal Density Probability (MDP) for Y (columns). for the Covariance I have the following.
np.cov(P)
array([[ 2.247e-04, 6.999e-05, 2.571e-05, -2.822e-05, 1.061e-04],
[ 6.999e-05, 2.261e-04, 9.535e-07, 8.165e-05, -2.013e-05],
[ 2.571e-05, 9.535e-07, 7.924e-05, 1.357e-05, -8.118e-05],
[-2.822e-05, 8.165e-05, 1.357e-05, 2.039e-04, -1.267e-04],
[ 1.061e-04, -2.013e-05, -8.118e-05, -1.267e-04, 2.372e-04]])
How do I get the MDP? Also, is there a way to use numpy to select just the X and Y vals and assign them to variables where X= P's rows and Y=P's columns?
CodePudding user response:
The data stored in P are a little ambiguous. In statistics, the X and Y have a very specific meaning. Usually, each row refers to one observation (i.e. datapoint) of some statistical object while the column represents a feature that is measured for each statistical object. In your case, there would be 9 observations with 5 features. This is referred to as a 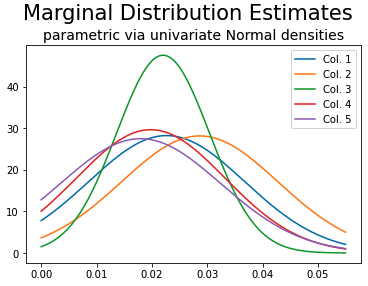
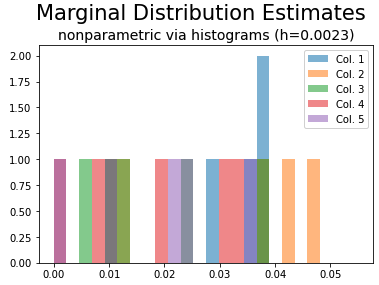
2. Nonparametric density estimation
Alternatively, you can use a histogram as a non-parametric estimator of the unknown probability density functions (of each column/feature). Note, however, that you still have to choose a bandwidth h that determines the width of the bins. Additionally, non-parametric tools require a larger sample size to provide accurate estimates. Your sample size 9 is likely insufficient.
import numpy as np
from matplotlib import pyplot as plt
# endpoints on all bins: implies bandwith h=0.00229
bins = np.linspace(0.0, 0.055, 25)
h = np.diff(bins)[0]
# histograms
for i in range(5):
plt.hist(P[:,i], bins, alpha=0.5, label='Col. {}'.format(i 1))
plt.suptitle('Marginal Distribution Estimates', fontsize=21, y=1.025)
plt.title('nonparametric via histograms (h={})'.format(round(h, 4)), fontsize=14)
plt.legend(loc='upper right')
plt.show()