I have the dataframe like this:
data = {'name': ['Alex', 'Ben', 'Marry','Alex', 'Ben', 'Marry'],
'job': ['teacher', 'doctor', 'engineer','teacher', 'doctor', 'engineer'],
'age': [27, 32, 78,27, 32, 78],
'weight': [160, 209, 130,164, 206, 132],
'date': ['6-12-2022', '6-12-2022', '6-12-2022','6-13-2022', '6-13-2022', '6-13-2022']
}
df = pd.DataFrame(data) df
I add data for another date as null values:
|name |job |age|weight |date
|---|-------|-----------|---|-------|--------
|0 |Alex |teacher |27 |160 |6-12-2022
|1 |Ben |doctor |32 |209 |6-12-2022
|2 |Marry |engineer |78 |130 |6-12-2022
|3 |Alex |teacher |27 |164 |6-13-2022
|4 |Ben |doctor |32 |206 |6-13-2022
|5 |Marry |engineer |78 |132 |6-13-2022
|6 |Alex |teacher |NaN|NaN |6-14-2022
|7 |Ben |doctor |NaN|NaN |6-14-2022
|8 |Marry |engineer |NaN|NaN |6-14-2022
Now, I want to fillna values in weight column after groupby name and job, and get average
I tried these lines of codes:
df.loc[df.weight.isnull(), 'weight'] = df.groupby(["name", "job"]).weight.transform('mean')
or
df['weight'] = df['weight'].fillna(df.groupby(["name", "job"])['weight'].mean())
or
df['weight'] = df.groupby(["name", "job"], sort=False)['weight'].apply(lambda x: x.fillna(x.mean()))
For the first one, I get this error:
ValueError: Buffer dtype mismatch, expected 'Python object' but got 'long'
name and job are string, and weight is flout64.
and for the rest it runs but doesnt fill na values.
CodePudding user response:
Try:
def fn(x):
x["age"].fillna(x["age"].mean(), inplace=True)
x["weight"].fillna(x["weight"].mean(), inplace=True)
return x
df = df.groupby(["name", "job"]).apply(fn)
print(df)
Prints:
name job age weight date
0 Alex teacher 27.0 160.0 6-12-2022
1 Ben doctor 32.0 209.0 6-12-2022
2 Marry engineer 78.0 130.0 6-12-2022
3 Alex teacher 27.0 164.0 6-13-2022
4 Ben doctor 32.0 206.0 6-13-2022
5 Marry engineer 78.0 132.0 6-13-2022
6 Alex teacher 27.0 162.0 6-14-2022
7 Ben doctor 32.0 207.5 6-14-2022
8 Marry engineer 78.0 131.0 6-14-2022
CodePudding user response:
You can't use mean with non numeric values, you must convert:
df.loc[df.weight.isnull(), 'weight'] = pd.to_numeric(df['weight']).groupby([df["name"], df["job"]]).transform('mean')
Output:
name job age weight date
0 Alex teacher 27 160 6-12-2022
1 Ben doctor 32 209 6-12-2022
2 Marry engineer 78 130 6-12-2022
3 Alex teacher 27 164 6-13-2022
4 Ben doctor 32 206 6-13-2022
5 Marry engineer 78 132 6-13-2022
6 Alex teacher NaN 162.0 6-14-2022
7 Ben doctor NaN 207.5 6-14-2022
8 Marry engineer NaN 131.0 6-1242022
CodePudding user response:
For your purpose using Andrej Kesely answer might be enough, but have in mind that using apply with pandas is not good performance-wise.
A better option to maintain performance is to use .transform('mean') like
df["age"].fillna(df.groupby(["name", "job"])["age"].transform("mean"), inplace=True)
df["weight"].fillna(df.groupby(["name", "job"])["weight"].transform("mean"), inplace=True)
This is just a comparison between the groupby and apply strategy and the transform one. Where slow referes to the groupby-apply and fast to the transform.
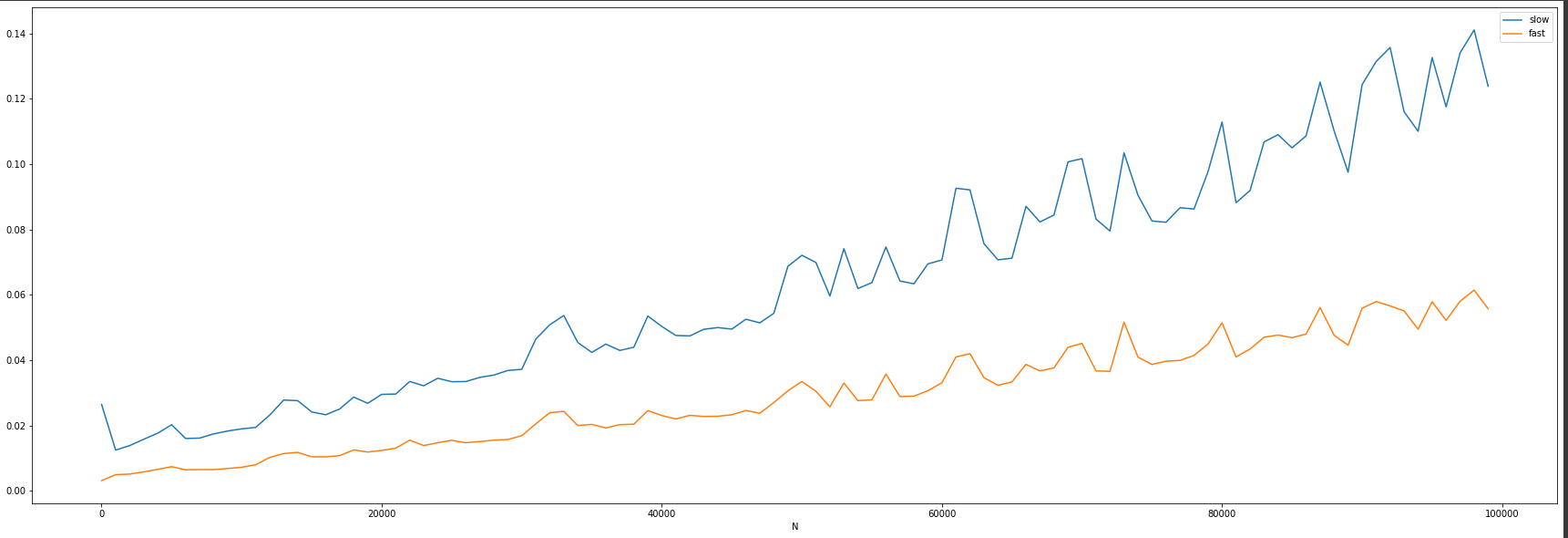
To reproduce this comparison you can run this
import numpy as np
import pandas as pd
import time
from tqdm import tqdm
def build_dataset(N):
names = ['Alex', 'Ben', 'Marry','Alex', 'Ben', 'Marry']
jobs = ['teacher', 'doctor', 'engineer','teacher', 'doctor', 'engineer']
data = {
'name': np.random.choice(names, size=N),
'job': np.random.choice(jobs, size=N),
'age': np.random.uniform(low=10, high=90, size=N),
'weight': np.random.uniform(low=60, high=150, size=N)
}
df = pd.DataFrame(data)
df.loc[df.sample(frac=0.1).index, "age"] = np.nan
df.loc[df.sample(frac=0.1).index, "weight"] = np.nan
return df
def slow_way(df):
df = df.copy()
def fn(x):
x["age"].fillna(x["age"].mean(), inplace=True)
x["weight"].fillna(x["weight"].mean(), inplace=True)
return x
return df.groupby(["name", "job"]).apply(fn)
def fast_way(df):
df = df.copy()
df["age"].fillna(df.groupby(["name", "job"])["age"].transform("mean"), inplace=True)
df["weight"].fillna(df.groupby(["name", "job"])["weight"].transform("mean"), inplace=True)
return df
Ns = np.arange(10, 100000, step=1000, dtype=np.int32)
slow = []
fast = []
size = []
for N in tqdm(Ns):
for i in range(10):
df = build_dataset(N)
start = time.time()
_ = slow_way(df)
end = time.time()
slow.append(end-start)
start = time.time()
_ = fast_way(df)
end = time.time()
fast.append(end-start)
size.append(N)
df = pd.DataFrame({"N": size, "slow": slow, "fast": fast})
df_group = df.groupby("N").mean()
df_group.plot(figsize=(30,10))