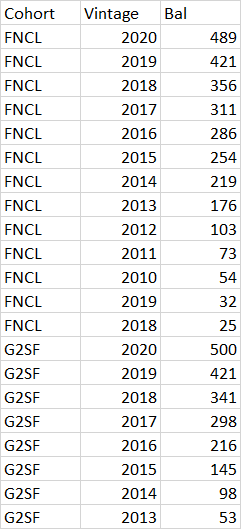
I have a dataframe read in from this excel file, if you look at FNCL 2019 and 2018 you'll see that those years (and only the Vintage column, not Bal) are duplicated. How could I raise an exception to prevent that from happening? It's not that 2019 and 2018 cannot show up multiple times in the Vintage column, but rather that, within the FNCL cohort (or any other for that matter), each Vintage cannot show up more than once.
CodePudding user response:
Assuming the first values are the correct ones, why not simply remove the rest? You can use the following to drop duplicate rows based on certain columns:
df_unique = df.drop_duplicates(subset=['Cohort', 'Vintage'])
CodePudding user response:
There are two different ways, depending on the expected outcome. If you want to combine the Bal entries for the same cohort and Vintage with a function 'f', then
df.groupby([ 'Cohort', 'Vintage' ]).agg( {'Bal':f} ).reset_index()
Otherwise, if you just want to drop the duplicates you can use (and keep the first row)
df.drop_duplicates(subset=['Cohort', 'Vintage'], keep='first')