I am trying to scrape a Webpage where some IDs need to be sought for. I am using Python with the Selenium Driver.
In order to access the search screen, I try to locate the "search" button and click on it. I have tried many methods to do this but I always get an exception in Python. I used to invoke these links with VBA IE scraping and it was really easy.
When inspecting the HTML on Chrome, the element is as follows:
"a target="content" href="search/search/BaseFormular.start"
id="Search.Customer" onm ouseover="nav_enter('NewSearch.Customer','by
Customer'); return true;" onclick="nav_enter('NewSearch.Customer','by
Customer'); return true;" onm ouseout="nav_leave('NewSearch.Customer','');
return true;">by Customer /a>
Does anyone have an idea on how I could possibly click on this element in Python with Selenium? Is there any way to write all WebElements on a page to a file in order to learn how to select them individually?
CodePudding user response:
You can find it by xpath like so:
driver.find_element_by_xpath('xpath_from_webpage').click()
to find the XPath you can (in chrome) right-click on the element, at the bottom of the list inspect:
your element should be highlighted, right-click then copy -> copy as XPath (or full XPath)
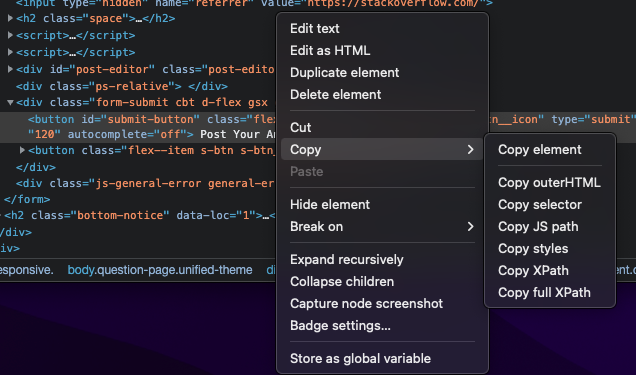
replace xpath_from_webpage in the code snippet above with the XPath you have just copied
CodePudding user response:
Excellent suggestion. It worked for me.
Endless thanks!