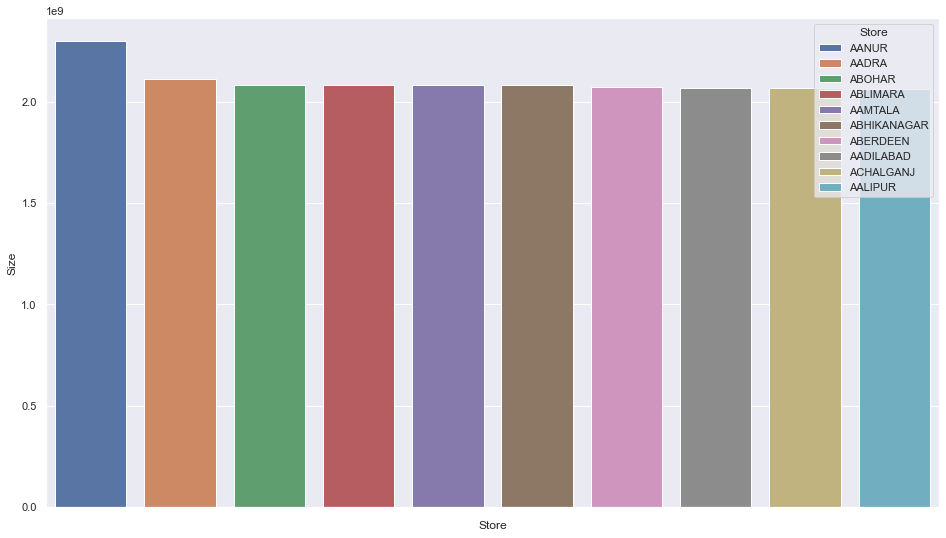
I need help plotting some categorical and numerical Values in python. the code is given below:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df=pd.read_csv('train_feature_store.csv')
df.info
df.head
df.columns
plt.figure(figsize=(20,6))
sns.countplot(x='Store', data=df)
plt.show()
Size = df[['Size','Store']].groupby(['Store'], as_index=False).sum()
Size.sort_values(by=['Size'],ascending=False).head(10)
However, the data size is so huge (Big data) that I'm not even able to make meaningful plotting in python. Basically, I just want to take the top 5 or top 10 values in python and make a plot of that as given below:-
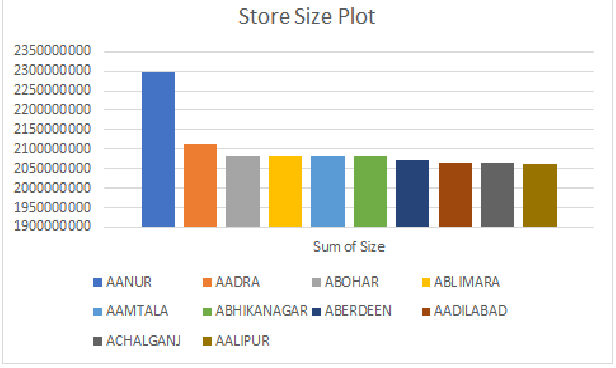
In an attempt to plot the thing, I'm trying to put the below code into a dataframe and plot it, but not able to do so. Can anyone help me out in this:-
Size = df[['Size','Store']].groupby(['Store'], as_index=False).sum()
Size.sort_values(by=['Size'],ascending=False).head(10)
Below, is a link to the sample dataset. However, the dataset is a representation, in the original one where I'm trying to do the EDA, which has around 3 thousand unique stores and 60 thousand rows of data. PLEASE HELP! Thanks!