These are the two dfs
Rating = ['A', 'AAA', 'AA', 'BBB', 'BB', 'B']
val = [4560.0, 64.0, 456.0, 34.0, 534.0, 54.0]
df = pd.DataFrame(dict(zip(Rating,val)),index=[0]).T
df.columns = ['values']
df1 = pd.DataFrame(['AA','AA','AA','AA','A','A'],columns=['Rating'])
df1.set_index('Rating',inplace=True)
df1 = df1.merge(df,left_index=True,right_index=True)
I used merge which work, but problem is it doesnt preserve the sequence of my original df1 dataFrame
df1 = df1.merge(df,left_index=True,right_index=True)
How can I run merge and preserve the sequence as well?
edited################
I get this output
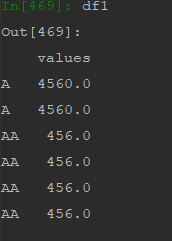
I want the sequencing to be what was in the original df i.e. ['AA','AA','AA','AA','A','A']
CodePudding user response:
df = pd.DataFrame({
'Rating' : ['A', 'AAA', 'AA', 'BBB', 'BB', 'B'],
'val' : [4560.0, 64.0, 456.0, 34.0, 534.0, 54.0]
})
df
###
Rating val
0 A 4560.0
1 AAA 64.0
2 AA 456.0
3 BBB 34.0
4 BB 534.0
5 B 54.0
Keeping df1 as yours, but don't set_index() additionally.
df1 = pd.DataFrame(['AA','AA','AA','AA','A','A'],columns=['Rating'])
df1
###
Rating
0 AA
1 AA
2 AA
3 AA
4 A
5 A
Doing the merge()
df1 = df1.merge(df,left_on='Rating', right_on='Rating')
df1
###
Rating val
0 AA 456.0
1 AA 456.0
2 AA 456.0
3 AA 456.0
4 A 4560.0
5 A 4560.0
Then set_index()
df1.set_index('Rating', inplace=True)
df1
###
val
Rating
AA 456.0
AA 456.0
AA 456.0
AA 456.0
A 4560.0
A 4560.0
With different df1
df1 = pd.DataFrame(['AA', 'A', 'A', 'A', 'AA', 'AA'], columns=['Rating'])
df1
###
Rating
0 AA
1 A
2 A
3 A
4 AA
5 AA
Doing the merge()
df1 = df1.merge(df,left_on='Rating', right_on='Rating', how='left')
df1
###
Rating val
0 AA 456.0
1 A 4560.0
2 A 4560.0
3 A 4560.0
4 AA 456.0
5 AA 456.0
CodePudding user response:
In this particular case, you can use sort_index() after the merging:
df1 = df1.merge(df,left_index=True,right_index=True).sort_index(ascending=False)
Returns:
values
AA 456.0
AA 456.0
AA 456.0
AA 456.0
A 4560.0
A 4560.0