I'm, new to data science methods so this is probably a basic question.
I have a dataset with daily observations but sometimes I get missing values for a couple of days and then an accumulated value for all the missing days. I know that total value is correct and I need (or, at least, it would be preferable, if possible) to use it to interpolate all those missing data.
This is a dummy example of the dataset I'm working with:
data <- data.frame(time=c(1:10), value=c(22,15,24,28,NA,NA,87,18,22,24))
Using the mean for the three days is not really an option since it is extremely rare for two days to have the same exact value, let alone consecutive days.
Is there any way to interpolate those days using the accumulated value or would I need to drop that observation and interpolate three days using something like splines, time series methods (SARIMA models) or neural nets?
CodePudding user response:
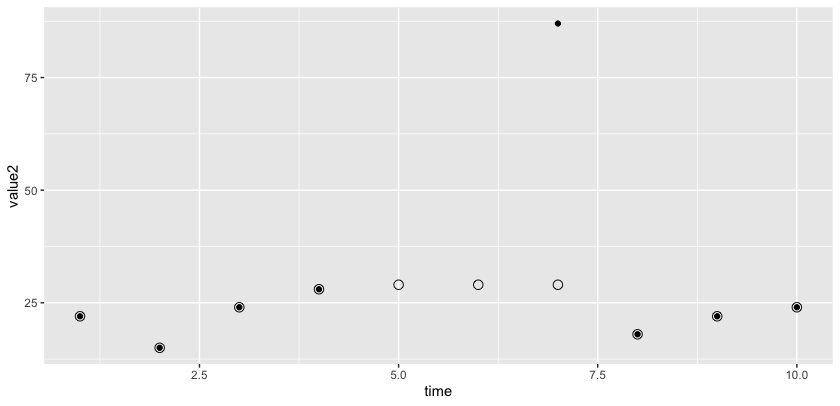
EDIT: We could fill in blanks using an average calculated with the "total." I understand you are looking for something fancier since flat readings are rare, but it's not clear from your description what specific pattern would be more likely. If you want it to look more plausible, you could add some noise to it...
library(dplyr)
data %>%
mutate(grp = cumsum(!is.na(lag(value)))) %>%
group_by(grp) %>%
mutate(value2 = sum(value, na.rm = TRUE) / n()) %>%
ggplot(aes(time, value2))
geom_point(aes(y = value))
geom_point(shape = 21, size = 3)
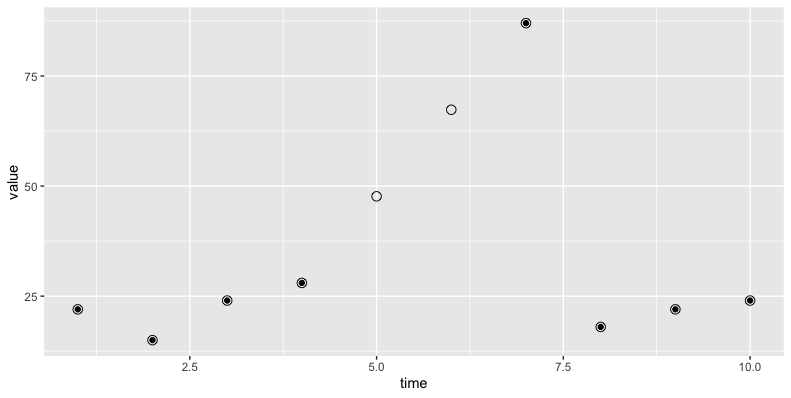
The approx function will handle linear interpolation:
data2 <- as.data.frame(approx(data$time, data$value, xout = 1:10))
library(ggplot2)
ggplot(data, aes(time, value))
geom_point()
geom_point(data = data2, aes(x, y), shape = 21, size = 3)
CodePudding user response:
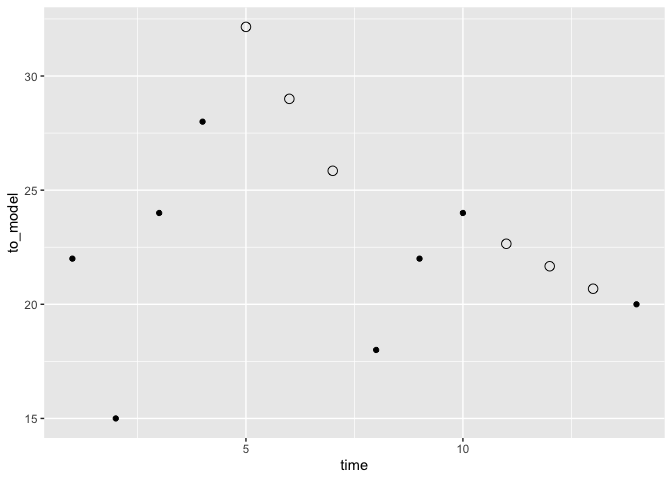
Maybe something like this with the approximated values re-apportioned based on the multi-day aggregates:
(I added a little extra made-up data to include a second run of NAs plus an aggregate.)
library(tidyverse)
# Sample data
data <- data.frame(time = c(1:14),
value = c(22, 15, 24, 28, NA, NA, 87, 18, 22, 24, NA, NA, 65, 20))
# Possible approach
data2 <- data |>
mutate(to_share = if_else(is.na(value) | is.na(lag(value, default = 1)), value, 0),
to_model = if_else(to_share == 0, value, NA_real_),
interpolated = approx(time, to_model, xout = time)$y,
interpolated = if_else(is.na(to_model), interpolated, NA_real_),
group = if_else(!is.na(to_model), 1, 2),
group = cumsum(group != lag(group, default = first(group)))
) |>
group_by(group) |>
mutate(sum_interpolated = sum(interpolated)) |>
fill(to_share, .direction = "up") |>
mutate(interpolated = interpolated / sum_interpolated * to_share,
new_value = coalesce(interpolated, value)) |>
ungroup()
data2 |>
ggplot(aes(time, to_model))
geom_point()
geom_point(aes(y = interpolated), shape = 21, size = 3)
Created on 2022-07-18 by the reprex package (v2.0.1)