I have a .txt file that looks like something like this:
<Location /git>
AuthType Basic
AuthName "Please enter your CVC username and password."
AuthBasicProvider LOCAL_authfile LDAP_CVCLAB LDAP_CVC007
AuthGroupFile /data/conf/git_group
#Require valid-user
Require group admins
Require group m4rtcdd
</Location>
# TEST
# SPACE
<Location /git/industry2go>
AuthType Basic
AuthName "Please enter your CVC username and password."
AuthBasicProvider LOCAL_authfile LDAP_CVCLAB LDAP_CVC007
AuthGroupFile /data/conf/git_group
#Require valid-user
Require group admins
Require group space_mobile_app
</Location>
<Location /git/sales2go-core>
AuthType Basic
AuthName "Please enter your CVC username and password."
AuthBasicProvider LOCAL_authfile LDAP_CVCLAB LDAP_CVC007
AuthGroupFile /data/conf/git_group
#Require valid-user
Require group admins
Require group space_mobile_app
</Location>
I need to make from this file a .xlsx file that needs to look like this:
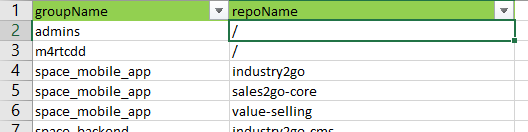
So basicly what should happen:
in the column name "groupName" should be group names that are taken from: "Require group admins, "Reguire group m4rtcdd"
in the column name "repoName" should pe the repository name that is taken from: "<Location /git> that means "/" (root) or for another example "<Location/git/industry2go> where "industry2go" its the "RepoName""
This is my script for the momement:
import pandas as pd
from svnscripts.timestampdirectory import createdir,path_dir
import time
import os
def gitrepoaccess():
timestr = time.strftime("%Y-%m-%d")
pathdest = path_dir()
df = pd.read_csv(rf"{pathdest}\{timestr}-rawGitData-conf.bck.txt",sep=';',lineterminator='\n',header=None)
#this is the drop of 0-32 line because was a big chunk file
df=df.drop(df.index[range(0,32)])
dest=createdir()
df.to_excel(os.path.join(dest, "GitRepoGroupAccess.xlsx"), index=False)
print(df)
gitrepoaccess()
I tried to use the delimiter but its not work cause also the "admins" category appears always and need to be displayed only once at the begining, as you can se in the raw.txt file its appearing in each "repository name".
CodePudding user response:
If the suggestion in my comment is fine, then this is your solution.
If it is not, please point out how you would prefer it and I will try to help you do that.
Either way, this can get you on the right path.
def extract(gits):
# get repo names in a colum
gits = gits.assign(repoName= gits[0][gits[0].str.startswith("<Location /git")])
# use ffill to match the reponame to the following rows of information
gits["repoName"] = gits.repoName.str.split("<Location /git").str[-1].str[1:-1].ffill()
# keep only rows with the group information
gits = gits[gits[0].str.startswith("Require group")].copy()
# set root repo to "/"
gits.loc[gits.repoName.eq(""), "repoName"] = "/"
# keep only the group name
gits["groupName"] = gits[0].str.split(" ").str[-1]
return gits[["groupName", "repoName"]].reset_index(drop= True)
In order for this function to work, you need a dataframe that has a row for every row in the text file, and only one column with name 0, which contains all the rows of the text file.
I saved your sample text in a file called "gits.txt". I assumed that there are no commas, which is why pd.read_csv works. You might have to use a different way to read it into the dataframe-format that I described.
From the console:
# pandas should not consider the first row a header
gits = pd.read_csv("gits.txt", header= None)
gits
>>>
0
0 <Location /git>
1 AuthType Basic
2 AuthName "Please enter your CVC username and password."
3 AuthBasicProvider LOCAL_authfile LDAP_CVCLAB LDAP_CVC007
4 AuthGroupFile /data/conf/git_group
5 #Require valid-user
6 Require group admins
7 Require group m4rtcdd
8 </Location>
9 # TEST
10 # SPACE
11 <Location /git/industry2go>
12 AuthType Basic
13 AuthName "Please enter your CVC username and password."
14 AuthBasicProvider LOCAL_authfile LDAP_CVCLAB LDAP_CVC007
15 AuthGroupFile /data/conf/git_group
16 #Require valid-user
17 Require group admins
18 Require group space_mobile_app
19 </Location>
20 <Location /git/sales2go-core>
21 AuthType Basic
22 AuthName "Please enter your CVC username and password."
23 AuthBasicProvider LOCAL_authfile LDAP_CVCLAB LDAP_CVC007
24 AuthGroupFile /data/conf/git_group
25 #Require valid-user
26 Require group admins
27 Require group space_mobile_app
28 </Location>
done = extract(gits)
done
>>>
groupName repoName
0 admins /
1 m4rtcdd /
2 admins industry2go
3 space_mobile_app industry2go
4 admins sales2go-core
5 space_mobile_app sales2go-core
The output is just a dataframe, save it however you like.
CodePudding user response:
The following code might give you what you need. I use regex to find all markup <Location></Location> tags, manipulate each line in each markup tag then save them to a dataframe.
import re
import pandas as pd
with open("data.txt") as f:
data = f.read()
locations = re.findall(r"<Location \S >[\s\S]*?(?:\n.*?<\/Location>)", data, flags=re.MULTILINE)
df = pd.DataFrame(columns=["groupName", "repoName"])
for location in locations:
lines = [line.strip() for line in location.split("\n") if line.startswith("<Location") or line.strip().startswith("Require group")]
repo_name = lines[0].split(" ")[-1][:-1] # get repository name
repo_name = "/" if repo_name == "/git" else repo_name.replace("/git/", "")
for line in lines[1:]: # start with 2nd lines to get each group name
if line.startswith("Require group"):
group_name = line.split(" ")[-1]
df = df.append({"groupName": group_name, "repoName": repo_name}, ignore_index=True)
Output:
| index | groupName | repoName |
|---|---|---|
| 0 | admins | / |
| 1 | m4rtcdd | / |
| 2 | admins | industry2go |
| 3 | space_mobile_app | industry2go |
| 4 | admins | sales2go-core |
| 5 | space_mobile_app | sales2go-core |