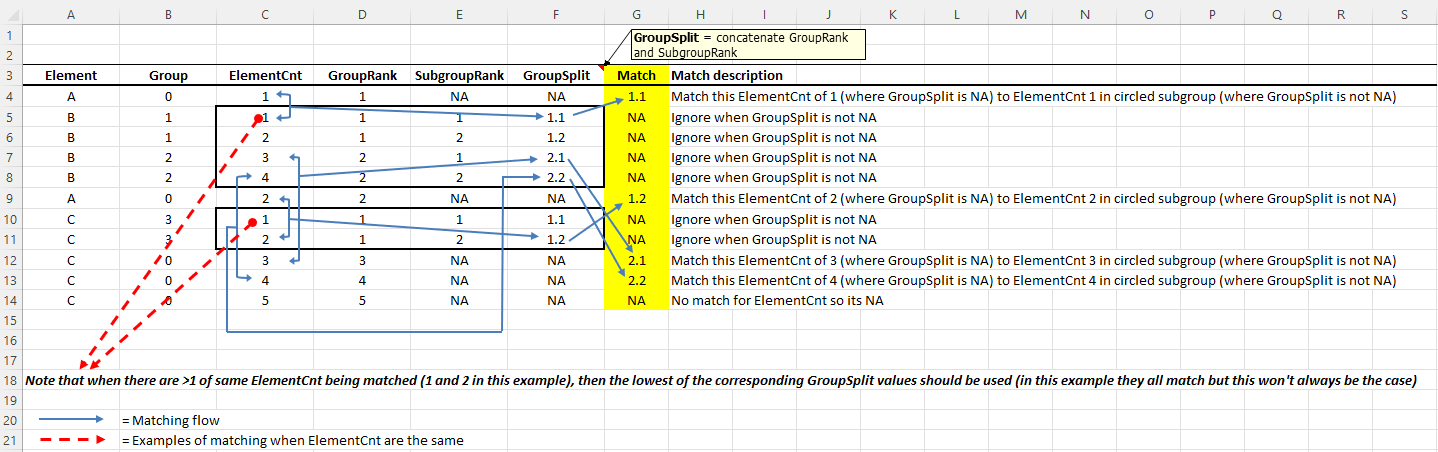
In the image shown immediately below, I am trying to replicate the yellow column labeled "Match" using dplyr. All columns except for "Match" and "Match description" are accurately generated with the reproducible code below.
Running this match requires some sort of subsetting of the dataframe into rows where GroupSplit is not NA (enclosed in heavy borders in the image below) - the values to match are inside these borders. Then, these matched values are imposed in the open cells where GroupSplit is NA as illustrated with arrows in the image below.
Also note, as stated at the bottom of the image, when there are duplicate rows for matching (Element Counts 1 and 2 in this example), the lowest of the applicable GroupSplit value is to be used; in this example, 1 and 2 have the same GroupSplit values but this will not always be the case.
Any recommendations for how to do this?
Reproducible code:
library(dplyr)
myData <-
data.frame(
Element = c("A","B","B","B","B","A","C","C","C","C","C"),
Group = c(0,1,1,2,2,0,3,3,0,0,0)
)
excelCopy <- myData %>%
group_by(Element) %>%
mutate(ElementCnt = row_number()) %>%
mutate(GroupRank = case_when(Group > 0 ~ match(Group, unique(Group)),TRUE ~ ElementCnt)) %>%
ungroup() %>%
group_by(Element, Group) %>%
mutate(SubgroupRank = ifelse(Group == 0, NA, row_number()))%>%
mutate(GroupSplit = case_when(!is.na(SubgroupRank) ~ as.numeric(paste(GroupRank,SubgroupRank,sep = '.'))))
print.data.frame(excelCopy)
CodePudding user response:
i believe this should work
library(data.table)
setDT(excelCopy)
#create a rownumber
excelCopy[, rownumber := .I]
# sort by groupSplit, so that the lowest number is always on top
setkey(excelCopy, GroupSplit)
excelCopy[is.na(GroupSplit),
match := excelCopy[is.na(GroupSplit), ][excelCopy[!is.na(GroupSplit), ],
match := i.GroupSplit,
on = .(ElementCnt)]$match][]
setkey(excelCopy, rownumber)
excelCopy[, rownumber := NULL][]
Element Group ElementCnt GroupRank SubgroupRank GroupSplit match
1: A 0 1 1 NA NA 1.1
2: B 1 1 1 1 1.1 NA
3: B 1 2 1 2 1.2 NA
4: B 2 3 2 1 2.1 NA
5: B 2 4 2 2 2.2 NA
6: A 0 2 2 NA NA 1.2
7: C 3 1 1 1 1.1 NA
8: C 3 2 1 2 1.2 NA
9: C 0 3 3 NA NA 2.1
10: C 0 4 4 NA NA 2.2
11: C 0 5 5 NA NA NA
CodePudding user response:
It seems as though you simply want to merge the rows that have a missing GroupSplit with the rows that don't have a missing GroupSplit, where the latter set is constrained to have the lowest GroupSplit value by ElementCnt.
# first, remove the grouping structure your your data preparation code
excelCopy <- ungroup(excelCopy)
# second, get the minimum GroupSplit value by ElementCnt, and left_join
# this back to original data
excelCopy %>%
group_by(ElementCnt) %>%
summarize(Match = min(GroupSplit,na.rm=T)) %>%
left_join(excelCopy, by="ElementCnt") %>%
mutate(Match=if_else(!is.na(GroupSplit),NA_real_,Match)) %>%
relocate(Match, .after=everything()) %>%
mutate(Match = if_else(is.infinite(Match),NA_real_,Match))
Output:
ElementCnt Element Group GroupRank SubgroupRank GroupSplit Match
<int> <chr> <dbl> <int> <int> <dbl> <dbl>
1 1 A 0 1 NA NA 1.1
2 1 B 1 1 1 1.1 NA
3 1 C 3 1 1 1.1 NA
4 2 B 1 1 2 1.2 NA
5 2 A 0 2 NA NA 1.2
6 2 C 3 1 2 1.2 NA
7 3 B 2 2 1 2.1 NA
8 3 C 0 3 NA NA 2.1
9 4 B 2 2 2 2.2 NA
10 4 C 0 4 NA NA 2.2
11 5 C 0 5 NA NA NA
Faster and more concise with data.table:
library(data.table)
setDT(excelCopy)
excelCopy[excelCopy[, .(Match = min(GroupSplit, na.rm=T)), ElementCnt],
on="ElementCnt"][!is.na(GroupSplit), Match:=NA ][]
Output:
Element Group ElementCnt GroupRank SubgroupRank GroupSplit Match
<char> <num> <int> <int> <int> <num> <num>
1: A 0 1 1 NA NA 1.1
2: B 1 1 1 1 1.1 NA
3: C 3 1 1 1 1.1 NA
4: B 1 2 1 2 1.2 NA
5: A 0 2 2 NA NA 1.2
6: C 3 2 1 2 1.2 NA
7: B 2 3 2 1 2.1 NA
8: C 0 3 3 NA NA 2.1
9: B 2 4 2 2 2.2 NA
10: C 0 4 4 NA NA 2.2
11: C 0 5 5 NA NA NA