I am currently trying to compute the contribution of a variable to the growth of a total. The formula is the following : On the period T - T' : the contribution of variable X to the growth of the total variable Y is defined like follows :
(Xt/Yt)*((Xt'-Xt)/Xt)*100
Here is my dataset :
structure(list(regroupement = c("Autres", "Ortho ( rhumato et rachis)",
"Rachis", "Chirurgie digestive", "Ophtalmo", "Uro-néphro", "Gynéco",
"ORL Stomato sf bouche et dent", "bouche et dents", "Tissus mou et chir plastique",
"Chir thoracique et vasculaire", "Chir thoracique", "Chir esth et hors sécu",
"Divers chir", "Gastro", "Endoscopies digestives", "Cardio Vasc (médecine)",
"Pneumologie", "Neurologie", "Soins palliatifs", "Vasculaire interventionnel",
"Divers médecine", "Accouchements", "Obstétrique autre (hors IVG)",
"IVG", "Néo nat", "Séances autres", "Total"), actes_2019 = c(10,
29520, 395, 14618, 5589, 6515, 4150, 866, 3458, 2137, 449, 0,
575, 2180, 9179, 36079, 311, 388, 714, 4, 0, 6024, 4028, 294,
292, 1, 1842, 129618), actes_2020 = c(8, 25451, 308, 12845, 4167,
7376, 2994, 337, 2206, 2107, 437, 4, 575, 1477, 7933, 30192,
218, 897, 267, 0, 11, 3740, 3348, 193, 118, 5, 737, 107951),
actes_2021 = c(18, 24055, 106, 13735, 5505, 8196, 3376, 352,
3035, 2571, 511, 8, 689, 1134, 6504, 42333, 161, 272, 138,
7, 0, 4682, 3226, 181, 82, 0, 61, 120938), sejours_2019 = c(4,
5493, 44, 2577, 2502, 1221, 852, 260, 1288, 540, 158, 0,
236, 397, 1631, 6992, 101, 63, 90, 1, 0, 1028, 1455, 148,
246, 1, 1820, 29148), sejours_2020 = c(2, 4946, 34, 2220,
1819, 1220, 574, 94, 801, 554, 140, 1, 221, 269, 1335, 5811,
79, 42, 58, 0, 1, 726, 1371, 109, 98, 5, 720, 23250), sejours_2021 = c(7,
5144, 21, 2523, 2416, 1451, 657, 111, 1106, 649, 162, 1,
278, 264, 1109, 7922, 69, 51, 30, 2, 0, 825, 1259, 108, 77,
0, 54, 26296)), row.names = c(4L, 5L, 6L, 7L, 8L, 9L, 10L,
11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L,
24L, 25L, 26L, 27L, 28L, 29L, 30L, 1L), core = structure(list(
regroupement = c("Autres", "Ortho ( rhumato et rachis)",
"Rachis", "Chirurgie digestive", "Ophtalmo", "Uro-néphro",
"Gynéco", "ORL Stomato sf bouche et dent", "bouche et dents",
"Tissus mou et chir plastique", "Chir thoracique et vasculaire",
"Chir thoracique", "Chir esth et hors sécu", "Divers chir",
"Gastro", "Endoscopies digestives", "Cardio Vasc (médecine)",
"Pneumologie", "Neurologie", "Soins palliatifs", "Vasculaire interventionnel",
"Divers médecine", "Accouchements", "Obstétrique autre (hors IVG)",
"IVG", "Néo nat", "Séances autres"), actes_2019 = c(10,
29520, 395, 14618, 5589, 6515, 4150, 866, 3458, 2137, 449,
0, 575, 2180, 9179, 36079, 311, 388, 714, 4, 0, 6024, 4028,
294, 292, 1, 1842), actes_2020 = c(8, 25451, 308, 12845,
4167, 7376, 2994, 337, 2206, 2107, 437, 4, 575, 1477, 7933,
30192, 218, 897, 267, 0, 11, 3740, 3348, 193, 118, 5, 737
), actes_2021 = c(18, 24055, 106, 13735, 5505, 8196, 3376,
352, 3035, 2571, 511, 8, 689, 1134, 6504, 42333, 161, 272,
138, 7, 0, 4682, 3226, 181, 82, 0, 61), sejours_2019 = c(4,
5493, 44, 2577, 2502, 1221, 852, 260, 1288, 540, 158, 0,
236, 397, 1631, 6992, 101, 63, 90, 1, 0, 1028, 1455, 148,
246, 1, 1820), sejours_2020 = c(2, 4946, 34, 2220, 1819,
1220, 574, 94, 801, 554, 140, 1, 221, 269, 1335, 5811, 79,
42, 58, 0, 1, 726, 1371, 109, 98, 5, 720), sejours_2021 = c(7,
5144, 21, 2523, 2416, 1451, 657, 111, 1106, 649, 162, 1,
278, 264, 1109, 7922, 69, 51, 30, 2, 0, 825, 1259, 108, 77,
0, 54)), class = "data.frame", row.names = 4:30), tabyl_type = "two_way", totals =
"row", class = c("tabyl",
"data.frame"))
I have computed for instance the contribution of the decline in the number of acts between 2020 and 2021 of the medical specialty "ortho" to the evolution of the total growth of the number of acts between these two years :
25451/107951 * ((24055 - 25451)/25451)*100
I would like to compute it for every specialty, on periods 2021-2020 and 2019-2021 in order to then plot a bar plot (not a stacked one), like the second one done here :
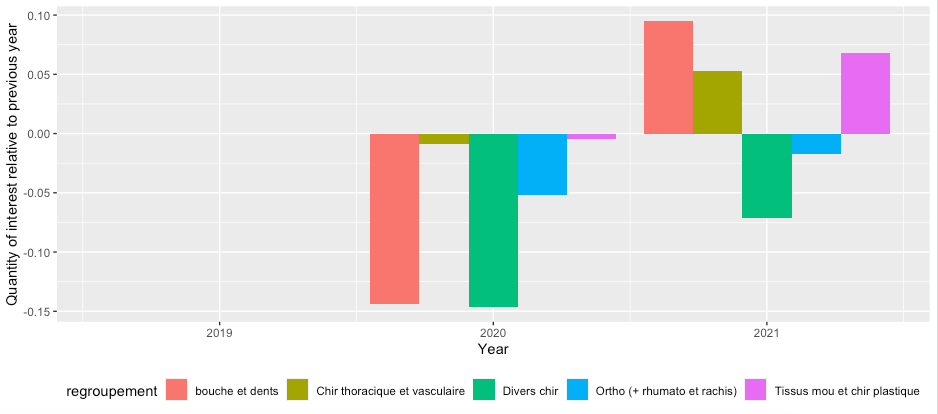
Explanation:
- Remove the "Total" row (it's never a good/tidy idea to mix marginals with raw data; instead calculate marginals on the fly).
- I randomly select some of the
regroupementcategories because keeping them all will give a very cluttered plot (you've got 28 categories). - Reshape
actes_*columns from wide to long and convert the names to years by removing"actes_"and then usingas.integer. - Calculate the quantity of interest; because data is in long format we can use
group_bywithdiffto calculate this very easily asvalue / sum(value) * c(NA, diff(value)) / value. Note that since we group byregroupement,sum(value)is simply the total perregroupement. If you instead want the grand total (I am not so clear on this point), you need to remove thegroup_by()andungroup()lines. - Plot as column plot with
position = "dodge".