I have a dataframe df as follows:
Col1 Col2
A1 A1
B1 A1
B1 B1
C1 C1
D1 A1
D1 B1
D1 D1
E1 A1
I am trying to achieve the following:
Col1 Group
A1 A1
B1 A1
D1 A1
E1 A1
C1 C1
i.e. in df every value which have relationship gets grouped together as a single value. i.e. in the example above (A1, A1), (B1, A1), (B1, B1), (D1, A1), (D1, B1), (D1, D1), (E1, A1) can either directly or indirectly be all linked to A1 (the first in alphabet sort) so they all get assigned the group id A1 and so on.
I am not sure how to do this.
CodePudding user response:
This can be approached using a graph.
Here is your graph:
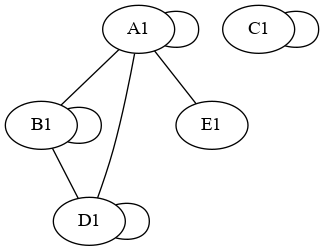
You can use networkx to find the connected_components:
import networkx as nx
G = nx.from_pandas_edgelist(df, source='Col1', target='Col2')
d = {}
for g in nx.connected_components(G):
g = sorted(g)
for x in g:
d[x] = g[0]
out = pd.Series(d)
output:
A1 A1
B1 A1
D1 A1
E1 A1
C1 C1
dtype: object