I have been seeing many warnings from sklearn type e.g:
FutureWarning: Feature names only support names that are all strings. Got feature names with dtypes: ['MyNewNames']. An error will be raised in 1.2.
while using StrEnum for the names of my features in regression anylises. I wrote the following code to ilustrate the case:
from enum import auto
from strenum import StrEnum
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.linear_model import LinearRegression
class MyNewNames(StrEnum):
MyCrim = auto()
MyZN = auto()
MyIndus = auto()
class ComputeRegression():
def SetUP(self,df:pd.DataFrame):
variables = [[MyNewNames.MyCrim,MyNewNames.MyZN],[MyNewNames.MyCrim,MyNewNames.MyIndus]]
for value in variables:
dX = df[value]
dY = df["AGE"]
self.ComputeRegression(dX,dY)
def ComputeRegression(self,dX,dY):
model = linear_model.LinearRegression()
model.fit(X = dX, y = dY)
predicted = model.predict(dX) # I see warnings when calling this line
print(predicted)
boston = datasets.load_boston()
df = pd.DataFrame(data= boston['data'], columns= boston['feature_names'])
df[MyNewNames.MyCrim] = df["CRIM"]
df[MyNewNames.MyZN] = df["ZN"]
df[MyNewNames.MyIndus] = df["INDUS"]
cr = ComputeRegression()
cr.SetUP(df)
It seems the issue is when I create a new column in the dataframe using the StrEnum, since when I change the following part of the code to:
df[MyNewNames.MyCrim.value] = df["CRIM"]
df[MyNewNames.MyZN.value] = df["ZN"]
df[MyNewNames.MyIndus.value] = df["INDUS"]
The warnings disapear. Can anyone explain to me why creating a new dataframe column with an enum "MyNewNames.Something" causes issues with the naming of the df column, while accessing a column like df[MyNewNames.MyIndus] is not a problem ?
Thanks!
CodePudding user response:
As of today, from my point of view, pandas.columns must be of python native type string because they are immutable and also an arbitrary choice of authors.
When you pass MyNewnames.Soemthing the object is of type enum. Like so:
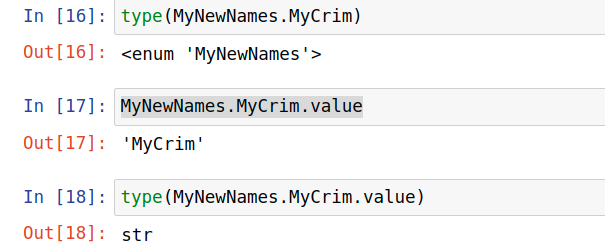
CodePudding user response:
The likely cause is that sklearn is doing a type check instead of an isinstance check for column names. That is:
if type(column_name) is str
instead of
if isinstance(column_name, str)