I am trying to create a line graph of the percentage of total events per group over time, I don't know if that wording entirely makes sense but hopefully the example will help
I have the following dataframes:
original_dataframe
|Group|Date |
|-----|----------|
|A |01/01/2022|
|A |01/01/2022|
|A |01/01/2022|
|A |01/01/2022|
|A |01/01/2022|
|A |01/01/2022|
|B |01/01/2022|
|B |01/01/2022|
|C |01/01/2022|
|C |01/01/2022|
|A |02/01/2022|
|A |02/01/2022|
|A |02/01/2022|
|B |02/01/2022|
|B |02/01/2022|
|B |02/01/2022|
|B |02/01/2022|
|B |02/01/2022|
|C |02/02/2022|
|C |02/02/2022|
summary_dataframe
|Group|Date |Count|
|-----|----------|-----|
|A |01/01/2022|6 |
|B |01/01/2022|2 |
|C |01/01/2022|2 |
|A |02/01/2022|3 |
|B |02/01/2022|5 |
|C |02/02/2022|2 |
And want to create a dataframe that contains the following for plotting:
|Group|Date |Perc|
|-----|----------|----|
|A |01/01/2022|60% |
|B |01/01/2022|20% |
|C |01/01/2022|20% |
|A |02/01/2022|30% |
|B |02/01/2022|50% |
|C |02/02/2022|20% |
CodePudding user response:
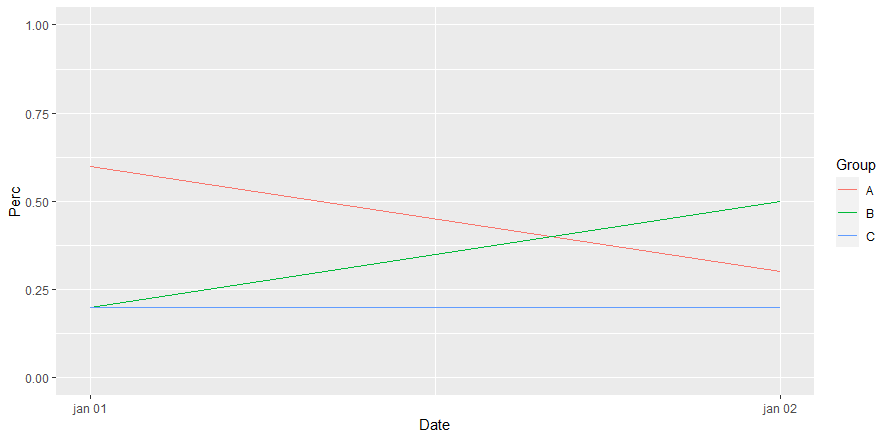
Something like below should get you there
I started out from the original data.frame. Everything is in one code block, but you can split the code where I marked it.
library(dplyr)
library(ggplot2)
df1 %>%
group_by(Date, Group) %>%
summarise(cnt = n()) %>%
mutate(Perc = cnt / sum(cnt)) %>% # split here to start ggplot with aggregated data.
ggplot(aes(x = Date, y = Perc, color = Group))
geom_line()
ylim(0, 1)
data:
df1 <- structure(list(Group = c("A", "A", "A", "A", "A", "A", "B", "B",
"C", "C", "A", "A", "A", "B", "B", "B", "B", "B", "C", "C"),
Date = structure(c(18993, 18993, 18993, 18993, 18993, 18993,
18993, 18993, 18993, 18993, 18994, 18994, 18994, 18994, 18994,
18994, 18994, 18994, 18994, 18994), class = "Date")), row.names = c(NA,
-20L), class = "data.frame")
CodePudding user response:
You can use group_by and summarise for this
library(tidyverse)
df <- structure(list(group_date = c("A", "A", "A", "A", "A", "A", "B",
"B", "C", "C", "A", "A", "A", "B", "B", "B", "B", "B", "C", "C"
), x = c("01/01/2022", "01/01/2022", "01/01/2022", "01/01/2022",
"01/01/2022", "01/01/2022", "01/01/2022", "01/01/2022", "01/01/2022",
"01/01/2022", "02/01/2022", "02/01/2022", "02/01/2022", "02/01/2022",
"02/01/2022", "02/01/2022", "02/01/2022", "02/01/2022", "02/02/2022",
"02/02/2022")), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-20L))
df %>%
count(group_date, x) %>%
group_by(x) %>%
summarise(group_date = group_date,
Perc = n*100/(sum(n)))
# A tibble: 6 × 3
# Groups: x [3]
x group_date Perc
<chr> <chr> <dbl>
1 01/01/2022 A 60
2 01/01/2022 B 20
3 01/01/2022 C 20
4 02/01/2022 A 37.5
5 02/01/2022 B 62.5
6 02/02/2022 C 100