I have a question regarding git. In the picture you can see a graph of my project git commit history. My feature branch (the blue line on the left side) and the master branch (the red on the right side).
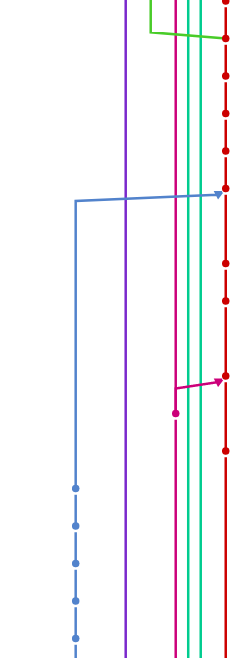
As you can see I worked some time on my feature and later decided to merge into master. That is displayed by the arrow that points to the red master branch.
Then I started working directly in the master and made some changes there which can also be seen in the picture.
The problem or the question is: When I wanted to checkout my old feature branch that should have been at the state before the merge into master I realized that my feature branch "followed" the master and all commits I made in master were also in my feature branch. I don't get that. How can that happen or did I miss something?
I merged into master and that shouldn't to anything to my feature branch. So why do all commits that I made in the master branch afterwards affect my feature branch? Hope someone has any idea.
I'm from Germany so English is not my first language tried my best to explain the problem.
CodePudding user response:
Git is not really about branches or files: it's really about commits. The dots on the lines represent the commits. Each commit has a unique hash ID, and that hash ID gets you that commit.
Each commit stores two things:
- a full snapshot of every file, as of the form it had (in Git's index aka staging area) when you told Git to make that commit; and
- some metadata, including things like the name and email address of the person who made the commit.
The snapshot is stored with all the file contents de-duplicated (within and across commits), so the fact that we mostly re-use most files from commit to commit means that the files actually take very little space. (They're further compressed, sometimes very much so, with tricky methods that we don't have to care about; just knowing that they're de-duplicated should make us comfortable with the idea of re-using files in each commit.)
The metadata, importantly, holds a list of previous commit hash IDs. For most commits, this "list" is just one entry long. It's what connects one dot in your graph to the previous dot. For a few commits, the list has two—technically, some integer n ≥ 2, but unless you get fancy it's just two—entries, and then you get that little arrow as well as the line. That's just how your graph-drawing software draws the graph. The actual storage is a list of hash IDs in each commit's metadata, remembering the hash ID for some previous commit(s).
The problem or the question is: When I wanted to checkout my old feature branch that should have been at the state before the merge into master I realized that my feature branch "followed" the master and all commits I made in master were also in my feature branch.
A branch name, in Git, is just a way Git gives us humans to work with commits where we (humans) don't have to memorize hash IDs. When you say git checkout old-feature-branch, the name old-feature-branch is simply a commit number. Git extracts the saved files from that commit.
When you use some viewer to look at commits, the graph it draws—if it draws one—is up to that viewer. The commits are joined by the hash IDs stored in their metadata: there is nothing more and nothing less; that's all there is to join commits. The branch names select one particular commit, and that's all they do. We say that the commit selected by the branch name is the tip commit of that branch.
We can start with the tip commit and work backwards. Since the hash IDs in the list in each commit are always hash IDs of previous commits,1 we can only work backwards. As we do work backwards, we find more commits. We usually say that some or all of the commits that we can find by doing this are "on the branch", whatever that means. But since multiple names can point to the same commit, and each merge commit points backwards to two or more previous commits, it's pretty likely that many commits are found by many names.
Indeed, the very first commit ever made, in some repository, is usually found by every branch name. This first commit is a bit special: its list of previous commits is empty, because there was no previous commit. It's where the action stops, and where history ends (or starts, if you like to think about time going forwards instead of backwards the way Git works). That is, in a sort of branch-y repository, if commit A is the very first commit and later commits are placed to the right, we get:
D <-- br1
/
C--E <-- br2
/
A--B
\
F--G <-- br4
\
H <-- br5
and as you can see, commits A and B are on every branch. Is there a name pointing to commit B? Well, there isn't in this drawing, but let's add one now:
D <-- br1
/
C--E <-- br2
/
A--B <-- br3
\
F--G <-- br4
\
H <-- br5
Commit A is still on every branch, but now that's five branches instead of four. If we delete name br4, commit G becomes un-find-able unless you've saved its hash ID somewhere, and now commit A is only on four branches.
So the set of branches that contains any given commit changes dynamically. The only surprise is that there's nothing surprising about this!