Such rows where all the values are 1. I wish to remove all such rows.
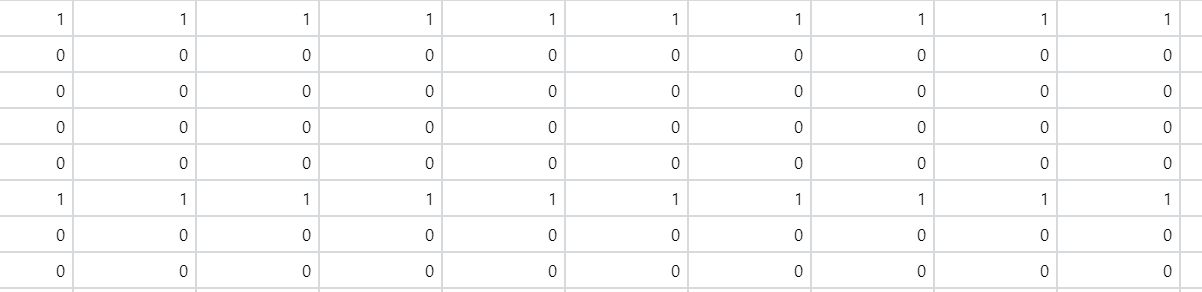
CodePudding user response:
Calling your data df,
df[rowSums(df == 1) < ncol(df), ]
rowSums(df == 1) is the count of 1s in each row. We keep rows where that is strictly less than the number of columns.
CodePudding user response:
For this we could use filter in combination with if_all:
library(dplyr)
df %>%
filter(if_all(everything(), ~ .x != 1))
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
1 0 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0 0 0
data:
structure(list(V1 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L), V2 = c(1L,
0L, 0L, 0L, 0L, 1L, 0L, 0L), V3 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L,
0L), V4 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L), V5 = c(1L, 0L, 0L,
0L, 0L, 1L, 0L, 0L), V6 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L),
V7 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L), V8 = c(1L, 0L, 0L,
0L, 0L, 1L, 0L, 0L), V9 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L
), V10 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L)), class = "data.frame", row.names = c(NA,
-8L))
CodePudding user response:
As these are 1s and 0s, an option is also with pmin
df[!do.call(pmin, df),]
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
2 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 0 0 0 0
8 0 0 0 0 0 0 0 0 0 0
Or using all with apply (less efficient)
df[!apply(df, 1, all),]
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
2 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 0 0 0 0
8 0 0 0 0 0 0 0 0 0 0
CodePudding user response:
Another base R option using lapply with Reduce like this:
df <- structure(list(V1 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L), V2 = c(1L,
0L, 0L, 0L, 0L, 1L, 0L, 0L), V3 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L,
0L), V4 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L), V5 = c(1L, 0L, 0L,
0L, 0L, 1L, 0L, 0L), V6 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L),
V7 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L), V8 = c(1L, 0L, 0L,
0L, 0L, 1L, 0L, 0L), V9 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L
), V10 = c(1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L)), class = "data.frame", row.names = c(NA,
-8L))
df[!Reduce(`&`, lapply(df, `==`, 1)),]
#> V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
#> 2 0 0 0 0 0 0 0 0 0 0
#> 3 0 0 0 0 0 0 0 0 0 0
#> 4 0 0 0 0 0 0 0 0 0 0
#> 5 0 0 0 0 0 0 0 0 0 0
#> 7 0 0 0 0 0 0 0 0 0 0
#> 8 0 0 0 0 0 0 0 0 0 0
Created on 2022-07-31 by the reprex package (v2.0.1)
Data from @TarJae, Thanks!