I have such type of dataset
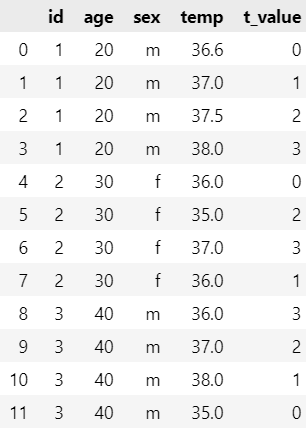
and want to do this dataset based on column 't_value'

I am pretty new to Python, I understand that we need to use loop but in what way? Also i dont know how to insert attractive tables with data( I would be gratfull for any help!
CodePudding user response:
You can use pivot_table() from pandas
try:
new_df = pd.pivot_table(
df, # the first dataframe
index = "id", # aggregating column
columns = "t_value" # mapped column
aggfunc = "first"
)
# merge the multiindex columns
new_df.columns = [x[0] "_" str(x[1]) for x in new_df.columns]
#reset index to retrieve "id" column
new_df.reset_index(inplace=True)
It is better than a 'for-loop'.
CodePudding user response:
I recommend using loops to .pivot the DataFrame, and then merging them.
import pandas as pd
from functools import partial, reduce
required_cols = ['age', 'sex', 'temp']
df_dict = {}
for col in applied_cols:
df[f'{col}_suffix'] = col '_' df['t_value'].astype(str)
temp_df = df.pivot(index='id', columns=f'{col}_suffix', values=col).reset_index()
df_dict[f'{col}_pivot'] = temp_df
merge_df = partial(pd.merge, on='id')
reduce(merge_df, df_dict.values())
Step 0: Creating DataFrame
Recreating DataFrame using the following:
import pandas as pd
data = {'id': [1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3],
'age': [20, 20, 20, 20, 30, 30, 30, 30, 40, 40, 40, 40],
'sex': ['m', 'm', 'm', 'm', 'f', 'f', 'f', 'f', 'm', 'm', 'm', 'm'],
'temp': [36.6, 37, 37.5, 38, 36, 35, 37, 36, 36, 37, 38, 35],
't_value': [0, 1, 2, 3, 0, 2, 3, 1, 3, 2, 1, 0]}
df = pd.DataFrame(data)
id age sex temp t_value
0 1 20 m 36.6 0
1 1 20 m 37.0 1
2 1 20 m 37.5 2
3 1 20 m 38.0 3
4 2 30 f 36.0 0
5 2 30 f 35.0 2
6 2 30 f 37.0 3
7 2 30 f 36.0 1
8 3 40 m 36.0 3
9 3 40 m 37.0 2
10 3 40 m 38.0 1
11 3 40 m 35.0 0
Step 1: Create new columns with values that will become column names in the final DataFrame
Currently, you do not have columns to pivot the table. We will create these using a for loop over the required column names:
required_cols = ['age', 'sex', 'temp']
for col in applied_cols:
df[f'{col}_suffix'] = col '_' df['t_value'].astype(str)
Output:
id age sex temp t_value age_suffix sex_suffix temp_suffix
0 1 20 m 36.6 0 age_0 sex_0 temp_0
1 1 20 m 37.0 1 age_1 sex_1 temp_1
2 1 20 m 37.5 2 age_2 sex_2 temp_2
Step 2: Pivot tables on the new columns
We will create a dictionary to hold these different pivot tables, then use a for loop to [pivot()][1] the DataFrame:
df_dict = {}
for col in applied_cols:
temp_df = df.pivot(index='id', columns=f'{col}_suffix', values=col).reset_index()
df_dict[f'{col}_pivot'] = temp_df
Output:
# table 1
age_suffix id age_0 age_1 age_2 age_3
0 1 20 20 20 20
1 2 30 30 30 30
2 3 40 40 40 40
# table 2
sex_suffix id sex_0 sex_1 sex_2 sex_3
0 1 m m m m
1 2 f f f f
2 3 m m m m
# table 3
temp_suffix id temp_0 temp_1 temp_2 temp_3
0 1 36.6 37.0 37.5 38.0
1 2 36.0 36.0 35.0 37.0
2 3 35.0 38.0 37.0 36.0
Step 3: we merge all three DataFrames into one
Here, we use a combination of pd.merge and functools:
from functools import partial, reduce
merge_df = partial(pd.merge, on='id')
reduce(merge_df, df_dict.values())
Output:
id age_0 age_1 age_2 age_3 sex_0 sex_1 sex_2 sex_3 temp_0 temp_1 temp_2 temp_3
0 1 20 20 20 20 m m m m 36.6 37.0 37.5 38.0
1 2 30 30 30 30 f f f f 36.0 36.0 35.0 37.0
2 3 40 40 40 40 m m m m 35.0 38.0 37.0 36.0
CodePudding user response:
Another option:
df['idx'] = df.groupby(['id', 'age', 'sex']).cumcount()
df1 = pd.pivot(df[['id','idx', 'age']],index = ['id'] ,values=['age'], columns=['idx']).add_prefix('age_')
df2 = pd.pivot(df[['id','idx', 'sex']],index = ['id'] ,values=['sex'], columns=['idx']).add_prefix('sex_')
df3 = pd.pivot(df[['id','idx', 'temp']],index = ['id'] ,values=['temp'], columns=['idx']).add_prefix('temp_')
df_final = df1.join(df2).join(df3)
print(df_final)