I have a dataset which has Id , ActivityDate and TotalSteps as column header. Please find dataframe details below:
df = pd.DataFrame([[1844505072, 6847, '4/1/2016'], [1844505072, 5367, '4/2/2016'], [1844505072, 0, '4/3/2016'],[1844505072, 0, '4/4/2016']], columns=['Id', 'TotalSteps','ActivityDate'])
Id TotalSteps ActivityDate
1844505072 6847 4/1/2016
1844505072 5367 4/2/2016
1844505072 0 4/3/2016
1844505072 0 4/4/2016
Need to find the total steps taken by each id and also the count when total_steps = 0. In the above set , expected result is:
Id TotalSteps Zero_steps
1844505072 12214 3
Below code is written using pandas which gives two separate results. I want all results to be in a single dataframe.
df[df['Id']==1844505072].groupby('Id').agg(Sum_Tot_Steps=('TotalSteps','sum'))
df[df['Id']==1844505072].groupby('Id')['TotalSteps'].apply(lambda x:x[x==0].count())
Please provide any solution using python pandas. Thanks for your help.
CodePudding user response:
Maybe here are the code:
import pandas as pd
data = {
"ID": ["1844505070","1844505070","1844505070","1844505071","1844505071","1844505071","1844505072","1844505072","1844505072"],
"DATE": ["4/1/2016","4/2/2016","4/3/2016","4/1/2016","4/2/2016","4/3/2016","4/1/2016","4/2/2016","4/3/2016"],
"STEPS": [6832,0,1329,0,0,539,1432,3198,7233],
}
df = pd.DataFrame(data)
Create sample data which is df:
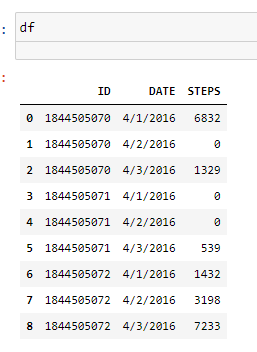
Statistics on the data
id_list = df["ID"].unique().tolist()
total_steps_list = []
zero_steps_list = []
for i in id_list:
tmp_df = df[df["ID"] == i]
total_steps_list.append(sum(tmp_df["STEPS"]))
zero_steps_list.append(len(tmp_df[tmp_df["STEPS"] == 0]))
result = {
"ID": id_list,
"TOTAL_STEPS": total_steps_list,
"ZERO_STEPS": zero_steps_list
}
df2 = pd.DataFrame(result)
And the result is df2:
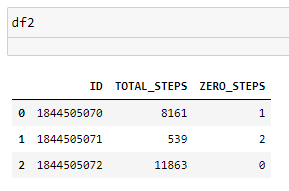
CodePudding user response:
use this code:
df = df.groupby(by=['id']).agg({'step': ['sum', lambda x: x.count(0)]}).reset_index()
also you can use from this:
import numpy as np
import pandas as pd
df['x'] = np.select([df.step == 0], [1], 0)
df = df.groupby(by=['id']).agg({'step': 'sum' , 'x': 'sum'}).reset_index()
CodePudding user response:
df = pd.DataFrame([[1844505072, 6847, '4/1/2016'], [1844505072, 5367, '4/2/2016'], [1844505072, 0, '4/3/2016'],[1844505072, 0, '4/4/2016']], columns=['Id', 'TotalSteps','ActivityDate'])
df.assign(Zero_steps = df.TotalSteps == 0).groupby('Id').sum()
Output:
TotalSteps Zero_steps
Id
1844505072 12214 2
CodePudding user response:
simple solution
Total_steps = df.groupby('Id')['Steps'].sum().reset_index(drop=True)
Zero_steps = df[df['Steps']==0].groupby('Id')['Steps'].count().reset_index(drop=True)
ID = df.groupby('Id')['Steps'].sum().index
data1 = {
'Id':ID,
'Total_steps':Total_steps,
'Zero_steps':Zero_steps
}
df2 = pd.DataFrame(data1)