I'm trying to add a new series to a dataframe that calculates the percent of group total. Thing is, I don't want a new dataframe. Here is my sample data:
df:
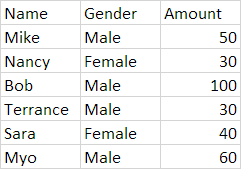
my desired output would be:
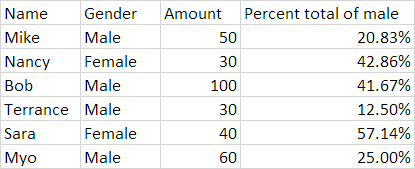
Any ideas, thanks in advance!
CodePudding user response:
Following BigBen's suggestion, you can calculate this as:
df['Percent total of male'] = df.groupby('Gender')['Amount'].transform(lambda x: x/x.sum())
Otherwise, in a more step-by-step approach you can also try:
df['Percent total of male'] = np.where(df['Gender'] == 'Male',df['Amount'] / df[df['Gender'] =='Male']['Amount'].sum(),df['Amount'] / df[df['Gender']!='Male']['Amount'].sum()
In which df['Amount'].sum() will be a scalar, and the division will calculate each rows value as % of total.