So i have a table that looks like this:
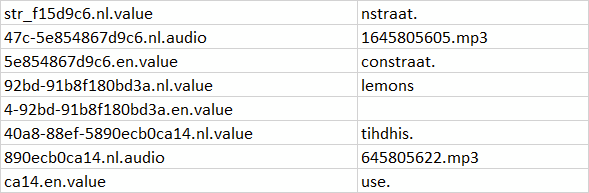
I want to search though the first column for every time i see nl.audio take the row on top, take the nl.audio row and the row right under it and move them to a new column so it looks like this:

not sure how to go about doing this.
the table comes from trying to get nested json values into a dataframe. like this
library(jsonlite)
library(tidyverse)
files <- list.files(path=".", pattern=".json", all.files=FALSE,
full.names=FALSE)
data <- fromJSON(files[1])
dat2 <- unlist(data$translation_map)
dat2 <- as.data.frame(dat2)
dput:
structure(list(dat2 = c("Iraat.",
" _1645805605.mp3",
"Ie.", "wn", "", "Wdis.",
"ewdewf.mp3",
"wedew.", "[k]ws.[/k]",
" _1645805740.mp3",
"edwedwedw.", "Ik ewwewe[/k].",
"we45805760.mp3",
"I h89.", "ewd3n", "", "ad23dt", "",
"Ik d2. ", "I d2d3.",
"Ha3d3d/k] 20.", "H3d20.",
"id3n", "", "straat")), row.names = c("str-5e854867d9c6.nl.value",
"str_f15f7751-227dc6.nl.audio", "str_f15f7751.en.value",
"str.nl.value", "str_172a516ca.en.value",
"str_4567f686.nl.value", "str_4.nl.audio",
"stcb0ca14.en.value", "str_622f99395.nl.value",
"str_622f9395.nl.audio", "str_622f90de9395.en.value",
"str_f25afe16.nl.value", "str_f2fad09045afe16.nl.audio",
"str_f2fad89045afe16.en.value", "s9e844c432e80.nl.value",
"str_b0c1b42e80.en.value", "str_e6d847f3-60b7-.nl.value",
"str_.en.value", "str_b61f9404-.nl.value",
"str_ b.en.value", "str_76e28ea6.nl.value",
"str-61a1b83bf1ba.en.value", "str_6280d5a49c42a24.nl.value",
"str5-0d5a49c42a24.en.value", "str_5e6b2202e748.nl.value"
), class = "data.frame")
CodePudding user response:
Something like this:
library(dplyr)
library(stringr)
df %>%
mutate(across(,str_squish)) %>%
mutate(A = ifelse(str_detect(V1, 'nl.audio'), lag(V2), NA_character_),
# B = str_extract(V2, '\\d .mp3'),
B = str_extract(V2, '.*.mp3$'),
C = ifelse(str_detect(V1, 'nl.audio'), lead(V2), NA_character_),
.keep= "unused") %>%
na.omit()
A B C
2 nstraat. 1645805605.mp3 constraat.
7 tihdhis. 645805622.mp3 use.
df <- structure(list(V1 = c("str_f15d9c6.nl.value", "47c-5e854867d9c6.nl.audio",
"5e854867d9c6.en.value", "92bd-91b8f180bd3a.nl.value", "4-92bd-91b8f180bd3a.en.value",
"40a8-88ef-5890ecbOca14.nl.value", "890ecbOca14.nl.audio", "ca14.en.value"
), V2 = c("\tnstraat.", "\t1645805605.mp3", "\tconstraat.", "\tlemons",
" \t", "\ttihdhis.", "\t645805622.mp3", "\tuse.")), class = "data.frame", row.names = c(NA,
-8L))
CodePudding user response:
We may need grep to find the index. Then add and subtract 1 to the index and extract the values from the second column based on that index (assuming data.frame columns)
i1 <- grep("nl.audio", df1[[1]], fixed = TRUE)
prev_ind <- i1-1
next_ind <- i1 1
data.frame(col1 = df1[[2]][prev_ind],
col2 = df1[[2]][next_ind],
col3 = df1[[2]][next_ind 1])