I have the following R code to fit a linear model on some data:
benchmark <- read.csv("data.csv")
model <- lm(formula = y ~ x, data = benchmark)
summary(model)
ggplot(benchmark, aes(x=x, y=y))
geom_point()
geom_smooth(method='lm', formula = y ~ x)
The result is:
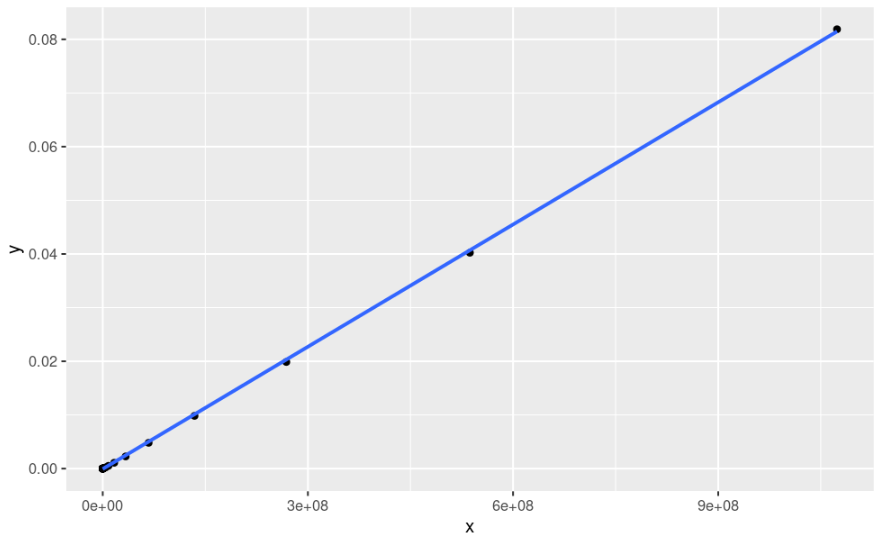
It looks weird to me because the axis are powers of two, so most data points are concentrated at the left. My guess is that it will be better to use a log-log scale, but i don't know how to do it properly. For example, using
scale_x_log10()
scale_y_log10()
i get now
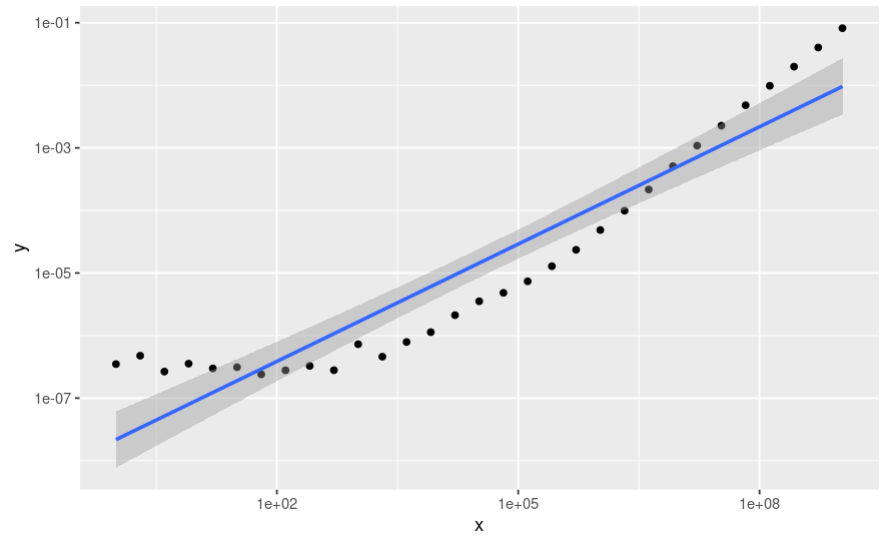
which i think is wrong.
EDIT: share the data
1, 3.50225e-07
2, 4.75979e-07
4, 2.65479e-07
8, 3.55327e-07
16, 2.98107e-07
32, 3.11732e-07
64, 2.40219e-07
128, 2.78199e-07
256, 3.27337e-07
512, 2.79105e-07
1024, 7.27129e-07
2048, 4.59182e-07
4096, 7.8944e-07
8192, 1.1326e-06
16384, 2.11749e-06
32768, 3.53295e-06
65536, 4.822e-06
131072, 7.3658e-06
262144, 1.2835e-05
524288, 2.34737e-05
1048576, 4.86131e-05
2097152, 9.87735e-05
4194304, 0.000215783
8388608, 0.000510538
16777216, 0.00108616
33554432, 0.00226483
67108864, 0.00480124
134217728, 0.00982463
268435456, 0.0198695
536870912, 0.0402285
1073741824, 0.0818823
CodePudding user response:
I believe that you are looking for the following.
glm code borrowed from a comment.
library(ggplot2)
library(scales)
ggplot(benchmark, aes(x=x, y=y))
geom_point()
geom_smooth(method = 'glm', formula = y ~ x, se = FALSE,
method.args = list(family = gaussian(link = 'log')))
scale_x_continuous(trans = 'log2',
breaks = trans_breaks("log2", function(x) 2^x),
labels = trans_format("log2", math_format(2^.x)))
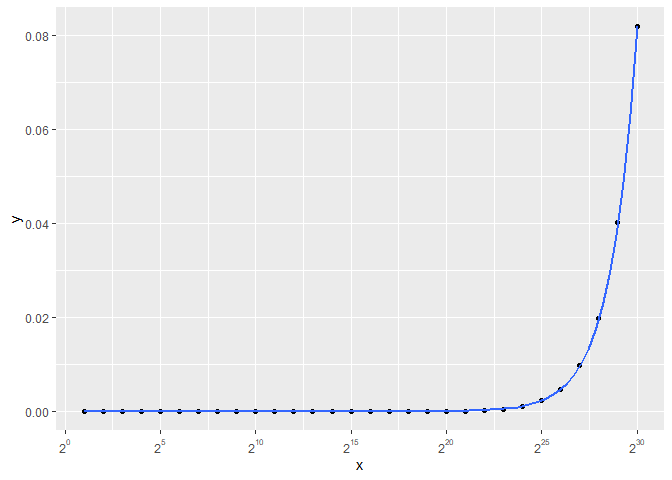
Created on 2022-08-07 by the reprex package (v2.0.1)
Data
x<-'1, 3.50225e-07
2, 4.75979e-07
4, 2.65479e-07
8, 3.55327e-07
16, 2.98107e-07
32, 3.11732e-07
64, 2.40219e-07
128, 2.78199e-07
256, 3.27337e-07
512, 2.79105e-07
1024, 7.27129e-07
2048, 4.59182e-07
4096, 7.8944e-07
8192, 1.1326e-06
16384, 2.11749e-06
32768, 3.53295e-06
65536, 4.822e-06
131072, 7.3658e-06
262144, 1.2835e-05
524288, 2.34737e-05
1048576, 4.86131e-05
2097152, 9.87735e-05
4194304, 0.000215783
8388608, 0.000510538
16777216, 0.00108616
33554432, 0.00226483
67108864, 0.00480124
134217728, 0.00982463
268435456, 0.0198695
536870912, 0.0402285
1073741824, 0.0818823
'
benchmark <- read.csv(textConnection(x))
names(benchmark) <- c("x", "y")
Created on 2022-08-07 by the reprex package (v2.0.1)