I would like to materialize for each row of a dataframe the corresponding group key it would get if I was using a groupby operation with a pandas Grouper.
import pandas as pd
# Test data
ts = [pd.Timestamp('2022/03/01 09:00'),
pd.Timestamp('2022/03/01 10:00'),
pd.Timestamp('2022/03/01 10:30'),
pd.Timestamp('2022/03/01 15:00')]
df = pd.DataFrame({'a':range(len(ts)), 'ts': ts})
grouper = pd.Grouper(key='ts', freq='2H', sort=False, origin='start_day')
Is there any way to get for each row the corresponding groupkey? The result I am looking for could be either a list, or a pandas Series or Index, or numpy array, the same length as the initial dataframe, and would then contain following values.
result = pd.Series([pd.Timestamp('2022-03-01 08:00:00'),
pd.Timestamp('2022-03-01 10:00:00'),
pd.Timestamp('2022-03-01 10:00:00'),
pd.Timestamp('2022-03-01 14:00:00')])
Thanks for your help! Bests
CodePudding user response:
Similar idea to @Andrej, just creates a table with a new column
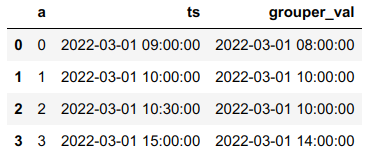
pd.concat(g.assign(grouper_val = i) for i,g in df.groupby(grouper))
CodePudding user response:
Not directly using the groupby but you can use:
df['ts'].dt.floor('2H')
With the groupby:
df.groupby(grouper)['ts'].transform(lambda g: g.name)
Output:
0 2022-03-01 08:00:00
1 2022-03-01 10:00:00
2 2022-03-01 10:00:00
3 2022-03-01 14:00:00
Name: ts, dtype: datetime64[ns]
CodePudding user response:
Given:
a ts
0 0 2022-03-01 09:00:00
1 1 2022-03-01 10:00:00
2 2 2022-03-01 10:30:00
3 3 2022-03-01 15:00:00
Doing:
pd.Series(df.resample('2H', origin='start_day', on='ts').groups)
Output:
2022-03-01 08:00:00 1
2022-03-01 10:00:00 3
2022-03-01 12:00:00 3
2022-03-01 14:00:00 4
dtype: int64