Let's say I have this table
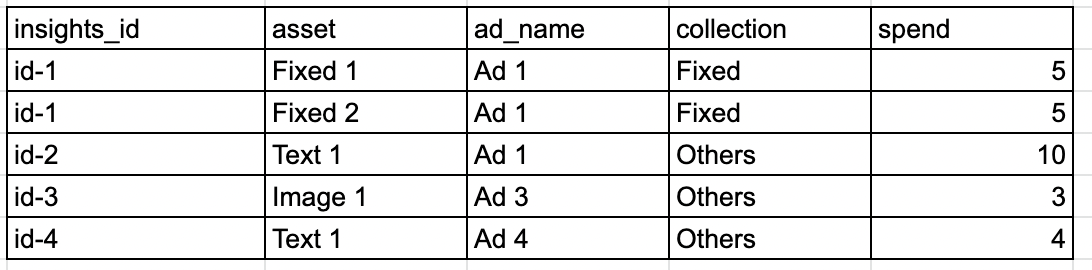
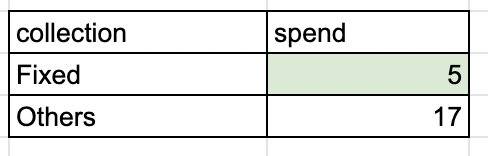
If I group by collection, to get the sum of spend, I will get the following result.

Now what I am struggling to figure out is how can I do a DISTINCT ON using insight_id, ad_name, and collection so it only keeps one of the two rows with the same values. In other words, how do I only select the first of the two rows/assets that have the same insight_id, ad_name, and collection before doing the group by to avoid discrepancy in the aggregation?

So the expected results would be
I am thinking of a query something like this
SELECT DISTINCT ON (insight_id, ad_name, collection)
collection,
SUM(spend)
FROM my_table
GROUP BY collection;
but the above query is apparently not working.
Another option is to use subquery but it goes well with what I am trying to achieve.
SELECT collection, SUM(spend)
FROM (SELECT DISTINCT ON (insight_id, ad_name, collection) FROM my_table)
GROUP BY collection;
CodePudding user response:
You're experiencing a normalisation issue: having asset and spend in the same table is causing problems. Apart from that, a readable and unambiguous solution could be:
select collection, sum(s) from (
select collection, min(spend) s
from my_table
group by insights_id, ad_name, collection
) sub
group by collection
Fiddle to test: http://sqlfiddle.com/#!9/7ade14/7/0
CodePudding user response:
You can use a simple query like
SELECT
collection,
SUM(DISTINCT spend)
FROM collections
GROUP BY collection
Also you can use ROW_NUMBER() OVER (PARTITION BY collection, spend ORDER BY spend) to mark duplicate values within group and then use the SUM function only with those values which row number value is 1.
Such a query looks like this
SELECT
collection,
SUM(spend)
FROM (
SELECT
collection,
spend,
ROW_NUMBER() OVER (PARTITION BY collection, spend ORDER BY spend) AS rn
FROM collections
) c
WHERE rn = 1
GROUP BY collection
You can check a working demo for both queries here
CodePudding user response:
You can make the distinction first and then apply aggregation. This query will probably work.
WITH cte AS (
SELECT DISTINCT insight_id, ad_name, collection, spend
FROM my_table
)
SELECT collection, SUM(spend)
FROM cte
GROUP BY collection;