i'm working on a dataset which represents the completion time of some activities performed in some processes. There are just 6 types of activities that repeat themselves throughout all the dataset and that are described by a numerical value. The example dataset is as follows:
name duration
1 10
2 12
3 34
4 89
5 44
6 23
1 15
2 12
3 39
4 67
5 47
6 13
I'm trying to check if the duration of the activity is normally distributed with the following code:
import numpy as np
import pylab
import scipy.stats as stats
import seaborn as sns
from scipy.stats import normaltest
measurements = df['duration']
stats.probplot(measurements, dist='norm', plot=pylab)
pylab.show()
ax = sns.distplot(measurements)
stat,p = normaltest(measurements)
print('stat=%.3f, p=%.3f\n' % (stat, p))
if p > 0.05:
print('probably gaussian')
else:
print('probably non gaussian')
But i want to do it for each type of activity, which means applying the stats.probplot(), sns.distplot() and the normaltest() to each group of activities (e.g. checking if all the activities called 1 have a duration which is normally distributed).
Any idea on how can i specify in the functions to return different plots for each group of activities?
CodePudding user response:
With the assumption that you have at least 8 samples per activity (as normaltest will throw an error if you don't) then you can loop through your data based on the unique activity values. You'll have to place pylab.show at the end of each graph so that they are not added to each other:
import numpy as np
import pandas as pd
import pylab
import scipy.stats as stats
import seaborn as sns
import random # Only needed by me to create a mock dataframe
import warnings # "distplot" is depricated. Look into using "displot"... in the meantime
warnings.filterwarnings('ignore') # I got sick of seeing the warning so I muted it
name = [1,2,3,4,5,6]*8
duration = [random.choice(range(0,100)) for _ in range(8*6)]
df = pd.DataFrame({"name":name, "duration":duration})
for name in df.name.unique():
nameDF = df[df.name.eq(name)]
measurements = nameDF['duration']
stats.probplot(measurements, dist='norm', plot=pylab)
pylab.show()
ax = sns.distplot(measurements)
ax.set_title(f'Name: {name}')
pylab.show()
stat,p = normaltest(measurements)
print('stat=%.3f, p=%.3f\n' % (stat, p))
if p > 0.05:
print('probably gaussian')
else:
print('probably non gaussian')
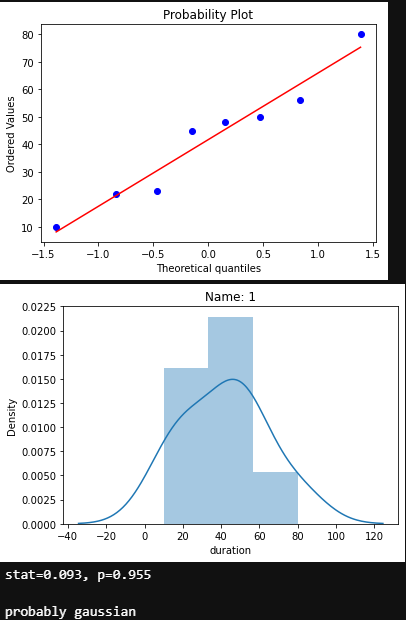
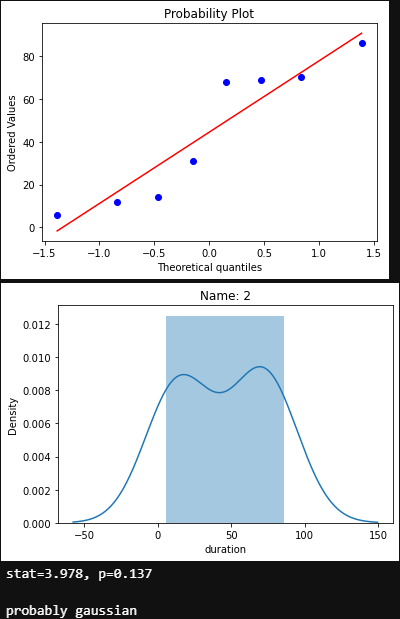
.
.
.
etc.