I have been looking for an answer without success (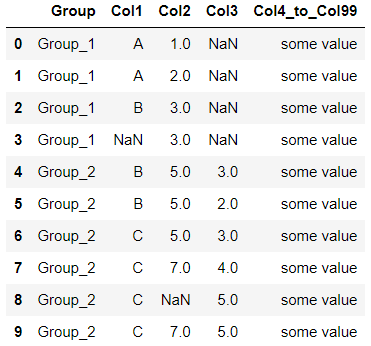
The function used for the output (
The output expected:
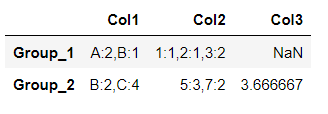
The output for Col1 and Col2 is a counting. The left side is the value, the right side is the count.
PD: If you know a more efficient way to implement join_non_nan_values function, you are welcome! (As it takes a while for it to run actually..) Just remember that it needs to skips missing values
CodePudding user response:
You can try this:
def f(x):
c = x.value_counts().sort_index()
return ";".join(f"{k}:{v}" for (k, v) in c.items())
df["Col2"] = df["Col2"].astype('Int64')
df.groupby("Group")[["Col1", "Col2", "Col3"]].agg({
"Col1": f,
"Col2": f,
"Col3": 'mean'
})
It gives:
Col1 Col2 Col3
Group
Group_1 A:2;B:1 1:1;2:1;3:2 NaN
Group_2 B:2;C:4 5:3;7:2 3.666667
CodePudding user response:
You can try calling value_counts() inside groupby().apply() and convert the outcome into strings using the str.join() method. To have a Frame (not a Series) returned as an output, use as_index=False parameter in groupby().
def func(g):
"""
(i) Count the values in Col1 and Col2 columns by calling value_counts() on each column
and convert the output into strings via join() method
(ii) Calculate mean of Col3
"""
col1 = ';'.join([f'{k}:{v}' for k,v in g['Col1'].value_counts(sort=False).items()])
col2 = ';'.join([f'{int(k)}:{v}' for k,v in g['Col2'].value_counts(sort=False).items()])
col3 = g['Col3'].mean()
return col1, col2, col3
# group by Group and apply func to specific columns
result = df.groupby('Group', as_index=False)[['Col1','Col2','Col3']].apply(func)
result
