I do have a data frame:
df = pd.DataFrame({'sample_ids':['sample1a_1', 'sample1b_2', 'sample1c_3', 'sample2a_2', 'sample2b_4'],
'perc_A':[0.75,0.66667,0.70213,0.83333,0.5],
'perc_B':[0.18182,0.24747,0.28176,0.16529,0.26316],
'perc_C':[0.4222,0.15823,0.17925,0.55556,0.21053]})
I would like to plot multiple 100% stacked and grouped bar charts based on the sample_ids. For example, sample1a_1, sample1b_2, sample1c_3 will be in one plot, while sample2a_2 and sample2b_4 will be in another plot. Another way of explanation, if the first six characters are the same, then the bar should be within the same figure.
Example of expected figures:
Figure N1:
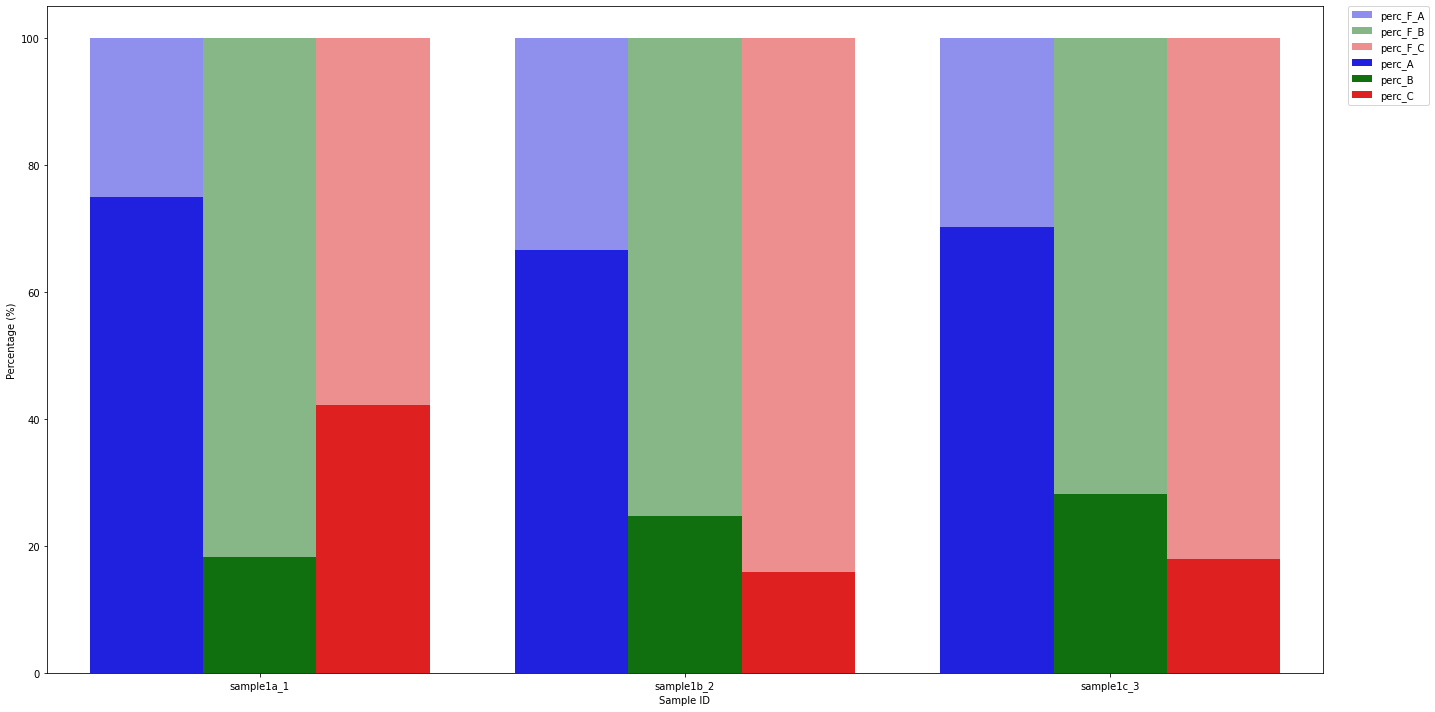
Figure N2:

Current code:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (20,10)
df = pd.DataFrame({'sample_ids':['sample1a_1', 'sample1b_2', 'sample1a_3', 'sample2a_2', 'sample2b_4'],
'perc_A':[0.75,0.66667,0.70213,0.83333,0.5],
'perc_B':[0.18182,0.24747,0.28176,0.16529,0.26316],
'perc_C':[0.4222,0.15823,0.17925,0.55556,0.21053]})
df[['perc_F_A', 'perc_F_B', 'perc_F_C']] = 1
meltedDF = df.melt(id_vars=['sample_ids'], var_name='perc', value_name='percent')
meltedDF['percent']=meltedDF['percent']*100
sns.barplot(data=meltedDF[meltedDF.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'], alpha=0.5)
sns.barplot(data=meltedDF[~meltedDF.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'])
plt.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0)
plt.xlabel("Sample ID")
plt.ylabel("Percentage (%)")
plt.show()
and current figure:
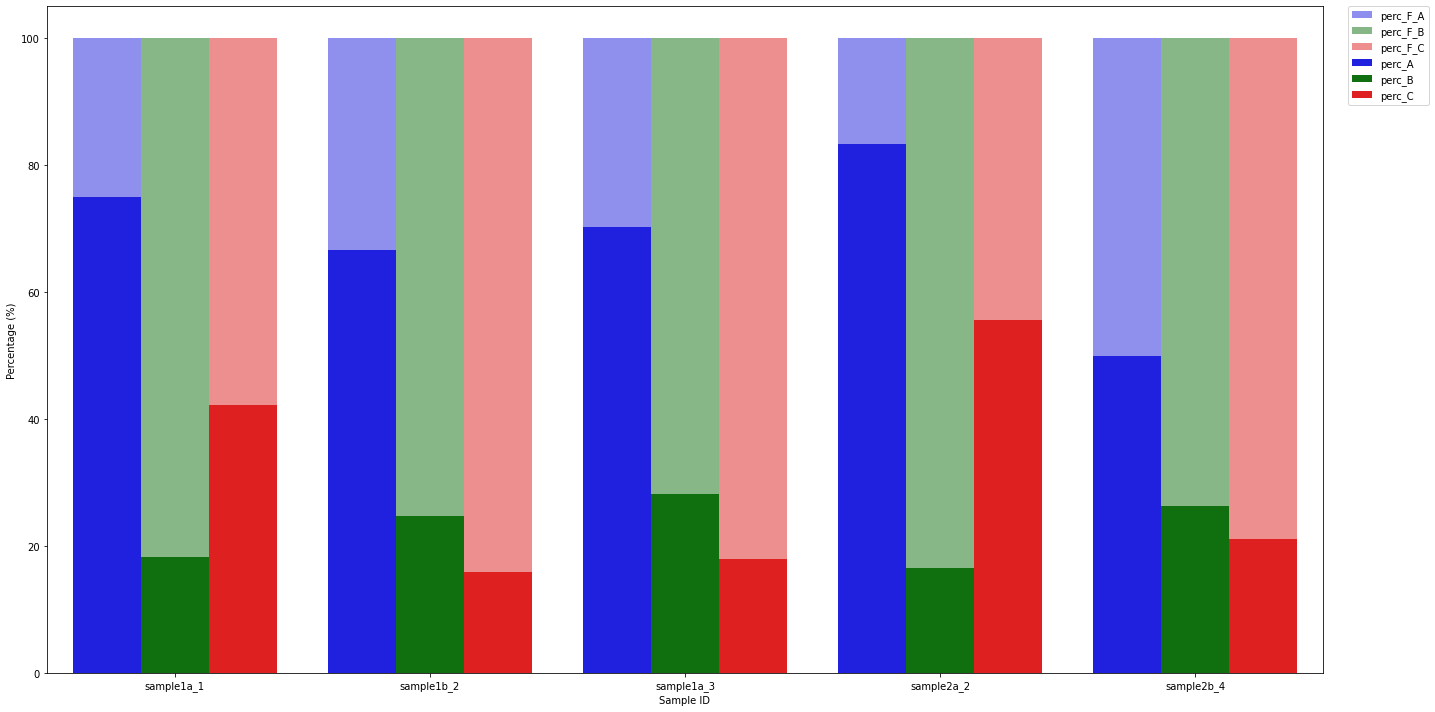
CodePudding user response:
You have manually create two subplots and get two axis
fig, (ax1, ax2) = plt.subplots(2)
And later you has to split data
v1 = meltedDF[ meltedDF['sample_ids'].isin(['sample1a_1', 'sample1b_2', 'sample1a_3']) ]
v2 = meltedDF[ meltedDF['sample_ids'].isin(['sample2a_2', 'sample2b_4']) ]
and draw them on different axis sns.barplot(..., ax=...)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (20,10)
df = pd.DataFrame({'sample_ids':['sample1a_1', 'sample1b_2', 'sample1a_3', 'sample2a_2', 'sample2b_4'],
'perc_A':[0.75,0.66667,0.70213,0.83333,0.5],
'perc_B':[0.18182,0.24747,0.28176,0.16529,0.26316],
'perc_C':[0.4222,0.15823,0.17925,0.55556,0.21053]})
df[['perc_F_A', 'perc_F_B', 'perc_F_C']] = 1
meltedDF = df.melt(id_vars=['sample_ids'], var_name='perc', value_name='percent')
meltedDF['percent'] = meltedDF['percent']*100
# --------------
fig, (ax1, ax2) = plt.subplots(2)
# --- plot 1 ---
v1 = meltedDF[ meltedDF['sample_ids'].isin(['sample1a_1', 'sample1b_2', 'sample1a_3']) ]
sns.barplot(ax=ax1, data=v1[v1.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'], alpha=0.5)
sns.barplot(ax=ax1, data=v1[~v1.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'])
ax1.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0)
ax1.set_xlabel("Sample ID") # plt.xlabel("Sample ID")
ax1.set_ylabel("Percentage (%)") # plt.ylabel("Percentage (%)")
# --- plot 2 ---
v2 = meltedDF[ meltedDF['sample_ids'].isin(['sample2a_2', 'sample2b_4']) ]
sns.barplot(ax=ax2, data=v2[v2.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'], alpha=0.5)
sns.barplot(ax=ax2, data=v2[~v2.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'])
ax2.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0)
ax2.set_xlabel("Sample ID") # plt.xlabel("Sample ID")
ax2.set_ylabel("Percentage (%)") # plt.ylabel("Percentage (%)")
# --------------
plt.show()
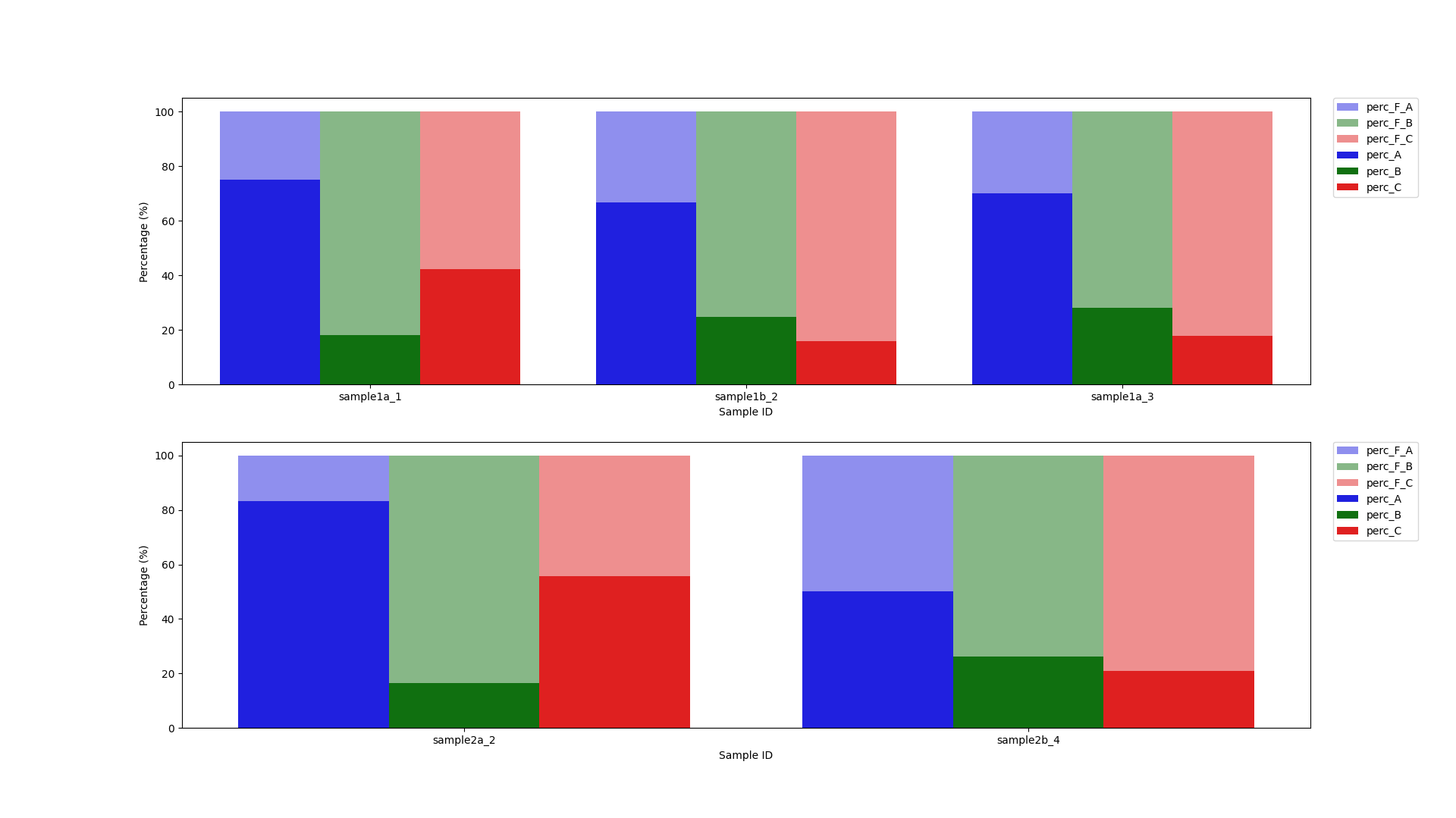
EDIT:
And if you want to automate it then you can use for-loop and dict to split it
splitted = {}
for item in df['sample_ids']:
prefix = item[:7]
if prefix not in splitted:
splitted[prefix] = []
splitted[prefix].append(item)
for key, val in splitted.items():
print(key, val)
Result:
sample1 ['sample1a_1', 'sample1b_2', 'sample1a_3']
sample2 ['sample2a_2', 'sample2b_4']
And later you can use for-loop to plot all subdata
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (20,10)
df = pd.DataFrame({'sample_ids':['sample1a_1', 'sample1b_2', 'sample1a_3', 'sample2a_2', 'sample2b_4'],
'perc_A':[0.75,0.66667,0.70213,0.83333,0.5],
'perc_B':[0.18182,0.24747,0.28176,0.16529,0.26316],
'perc_C':[0.4222,0.15823,0.17925,0.55556,0.21053]})
df[['perc_F_A', 'perc_F_B', 'perc_F_C']] = 1
meltedDF = df.melt(id_vars=['sample_ids'], var_name='perc', value_name='percent')
meltedDF['percent'] = meltedDF['percent']*100
# --------------
splitted = {}
for item in df['sample_ids']:
prefix = item[:7]
if prefix not in splitted:
splitted[prefix] = []
splitted[prefix].append(item)
for key, val in splitted.items():
print(key, val)
# --------------
fig, axs = plt.subplots(len(splitted))
for ax, (key, val) in zip(axs, splitted.items()):
subdata = meltedDF[ meltedDF['sample_ids'].isin(val) ]
sns.barplot(ax=ax, data=subdata[subdata.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'], alpha=0.5)
sns.barplot(ax=ax, data=subdata[~subdata.perc.str.contains('F')], x='sample_ids', y='percent', hue='perc', palette=['blue','green','red'])
ax.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0)
ax.set_xlabel("Sample ID") # plt.xlabel("Sample ID")
ax.set_ylabel("Percentage (%)") # plt.ylabel("Percentage (%)")
# --------------
plt.show()
EDIT:
You may also try to split it using groupby()
for key, val in df.groupby(df['sample_ids'].str[:7]):
print('---', key, '---')
#print(val['sample_ids'])
print(val)
Result:
--- sample1 ---
sample_ids perc_A perc_B perc_C perc_F_A perc_F_B perc_F_C
0 sample1a_1 0.75000 0.18182 0.42220 1 1 1
1 sample1b_2 0.66667 0.24747 0.15823 1 1 1
2 sample1a_3 0.70213 0.28176 0.17925 1 1 1
--- sample2 ---
sample_ids perc_A perc_B perc_C perc_F_A perc_F_B perc_F_C
3 sample2a_2 0.83333 0.16529 0.55556 1 1 1
4 sample2b_4 0.50000 0.26316 0.21053 1 1 1