I have a dataframe named df like
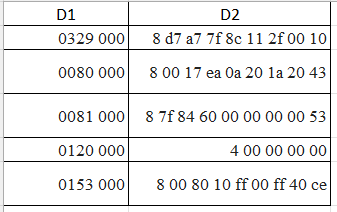
I want to split it like this in python.
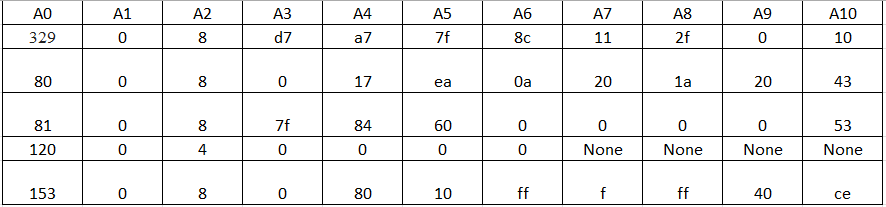
Any suggestion are appreciated.
data = {
"D1" : ["0329 000", "0080 000", "0081 000", "0120 000", "0153 000"],
"D2" : ["8 d7 a7 7f 8c 11 2f 00 10", "8 00 17 ea 0a 20 1a 20 43", "8 7f 84 60 00 00 00 00 53", "4 00 00 00 00", "8 00 80 10 ff 00 ff 40 ce"],
}
Thanks in advance
CodePudding user response:
Here is another way even removing some leading zero's.
import numpy as np
import pandas as pd
data = {
"D1" : ["0329 000", "0080 000", "0081 000", "0120 000", "0153 000"],
"D2" : ["8 d7 a7 7f 8c 11 2f 00 10", "8 00 17 ea 0a 20 1a 20 43", "8 7f 84 60 00 00 00 00 53", "4 00 00 00 00", "8 00 80 10 ff 00 ff 40 ce"],
}
df = pd.DataFrame(data)
df2 = pd.DataFrame(columns=['A' str(i) for i in range(11)])
df2['A0'] = df['D1'].str.split(' ', expand=True)[0]
df2['A1'] = df['D1'].str.split(' ', expand=True)[1]
df2['A2'] = df['D2'].str.split(' ', expand=True)[0]
df2['A3'] = df['D2'].str.split(' ', expand=True)[1]
df2['A4'] = df['D2'].str.split(' ', expand=True)[2]
df2['A5'] = df['D2'].str.split(' ', expand=True)[3]
df2['A6'] = df['D2'].str.split(' ', expand=True)[4]
df2['A7'] = df['D2'].str.split(' ', expand=True)[5]
df2['A8'] = df['D2'].str.split(' ', expand=True)[6]
df2['A9'] = df['D2'].str.split(' ', expand=True)[7]
df2['A10'] = df['D2'].str.split(' ', expand=True)[8]
df2 = df2.apply(lambda x: x.astype(int) if x.name in ['A0', 'A1'] else x)
Output:
A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10
0 329 0 8 d7 a7 7f 8c 11 2f 00 10
1 80 0 8 00 17 ea 0a 20 1a 20 43
2 81 0 8 7f 84 60 00 00 00 00 53
3 120 0 4 00 00 00 00 None None None None
4 153 0 8 00 80 10 ff 00 ff 40 ce
I can't seem to figure out the double zeros 00 and changing it to a single zero 0.
Hope this helps.
CodePudding user response:
Just split each cell and concat the result:
df1 = df["D1"].str.split(" ", expand=True)
df2 = df["D2"].str.split(" ", expand=True)
new_df = pd.concat([df1, df2], axis=1, ignore_index=True)
new_df.columns = ['A0', 'A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7', 'A8', 'A9', 'A10']
print(new_df)
Output:
A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10
0 0329 000 8 d7 a7 7f 8c 11 2f 00 10
1 0080 000 8 00 17 ea 0a 20 1a 20 43
2 0081 000 8 7f 84 60 00 00 00 00 53
3 0120 000 4 00 00 00 00 None None None None
4 0153 000 8 00 80 10 ff 00 ff 40 ce
CodePudding user response:
using str.strip():
tmp = df['D1'].str.cat(df['D2'], sep=' ')
out = tmp.str.split(expand=True).add_prefix('A')
output :
>>
A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10
0 0329 000 8 d7 a7 7f 8c 11 2f 00 10
1 0080 000 8 00 17 ea 0a 20 1a 20 43
2 0081 000 8 7f 84 60 00 00 00 00 53
3 0120 000 4 00 00 00 00 None None None None
4 0153 000 8 00 80 10 ff 00 ff 40 ce
CodePudding user response:
You can use chain.from_iterable and pandas.apply with axis=1 and at the end use pandas.applymap for apply function for converting each value to int.
from itertools import chain
# We can use the below function for converting all values to 'int' if we can
def to_int(x):
try:
return int(x)
except ValueError:
return x
df = df.apply(lambda row:
pd.Series(chain.from_iterable(row.str.split())), axis=1
).add_prefix('A'
).applymap(to_int)
print(df)
A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10
0 329 0 8 d7 a7 7f 8c 11.0 2f 0.0 10
1 80 0 8 0 17 ea 0a 20.0 1a 20.0 43
2 81 0 8 7f 84 60 0 0.0 0 0.0 53
3 120 0 4 0 0 0 0 NaN NaN NaN NaN
4 153 0 8 0 80 10 ff 0.0 ff 40.0 ce
What is chain.from_iterable?
from itertools import chain
list(chain.from_iterable([
[1,2],
[3,4]
]))
# [1, 2, 3, 4]