m2 = m.groupby('month_year')[
['units', 'revenue', 'transactions', 'Sessions', 'Bing Ads',
'Criteo','Facebook', 'Google Ads', 'Google Shopping']
].corr()
This is what i am doing but getting nan idk why?
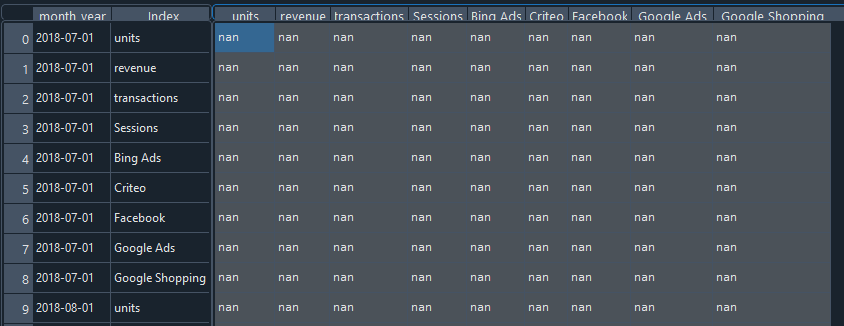
{kind=link}
CodePudding user response:
From the raw data you added, I don't see shared dates between observations. Here's an example:
data = [
["day 1", 88, 23, 20],
["day 2",-5, 78, 14],
["day 3",8, 35, 14],
["day 4",-3, 33, 155],
["day 5",88, 28, 80],
]
df = pd.DataFrame(data, columns=["id","a", "b", "c"])
df.groupby("id")[["a", "b","c"]].corr()
Here there are 5 days, none in common, as your raw data shows. This will return a df of NAs:
a b c
id
day 1 a NaN NaN NaN
b NaN NaN NaN
c NaN NaN NaN
day 2 a NaN NaN NaN
b NaN NaN NaN
c NaN NaN NaN
day 3 a NaN NaN NaN
b NaN NaN NaN
c NaN NaN NaN
day 4 a NaN NaN NaN
b NaN NaN NaN
c NaN NaN NaN
day 5 a NaN NaN NaN
b NaN NaN NaN
c NaN NaN NaN
If you have dates in common instead:
data = [
["day 1", 88, 23, 20],
["day 1",-5, 78, 14],
["day 1",8, 35, 14],
["day 2",-3, 33, 155],
["day 2",88, 28, 80],
]
df = pd.DataFrame(data, columns=["id","a", "b", "c"])
df.groupby("id")[["a", "b","c"]].corr()
Will result in:
a b c
id
day 1 a 1.000000 -1.000000 1.000000
b -1.000000 1.000000 -1.000000
c 1.000000 -1.000000 1.000000
day 2 a 1.000000 -0.924148 -0.147259
b -0.924148 1.000000 -0.241780
c -0.147259 -0.241780 1.000000
From the images posted this is my conclusion.