I want to plot bar graph from the dataframe below.
df2 = pd.DataFrame({'URL': ['A','A','B','B','C','C'],
'X': [5,0,7,1,0,0],
'Y': [4,0,4,7,9,0],
'Z':[11,0,8,4,0,0]})
URL X Y Z
0 A 5 4 11
1 A 0 0 0
2 B 7 4 8
3 B 1 7 4
4 C 0 9 0
5 C 0 0 0
The URL counts should be on the y-axis, and X, Y, Z categories should be on the x-axis with two bars for each.
I have done the first bar (code at the end): it will show the number of non-zero values in each column.
I need help with the second bar:
it should show how many (duplicate) URLs have at least 1 non-zero corresponding X, Y or Z value.
For example:
Acomes two times in theURL, and in theX-column we have one non-zero value - so it will count as 1.In the case of
B: both values are non-zero, so we will countBas 1 as well.But in the case of
C: since both values are 0 inXwe will not count it as one.
The same goes for Y and Z.
I have managed to draw a bar graph for the first case, but for the second one I'm unable to:
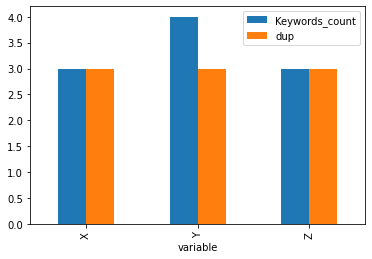
(df2.melt("URL")
.groupby("variable")
.agg(Keywords_count = ("value", lambda x: sum(x != 0)),
dup = ("URL", "nunique"))
.plot(kind="bar") )
plt.show()
CodePudding user response:
Use .apply() instead of .agg().
.apply can take the whole dataframe for each group (and thus can combine information from multiple columns), while .agg operates only on one column at a time.
def f(df):
n_non_zero_vals = (df["value"] != 0).sum()
# # If only duplicated URLs should be considered:
# df = df[df['URL'].duplicated(keep=False)]
# # Alternative:
# df = df.groupby("URL").filter(lambda x: len(x) > 1)
n_urls = df.groupby("URL")["value"].agg("any").sum()
return pd.Series([n_non_zero_vals, n_urls],
index=['Keywords_count', 'dup'])
(df2.melt("URL")
.groupby("variable")
.apply(f)
.plot(kind="bar") )
plt.show()
