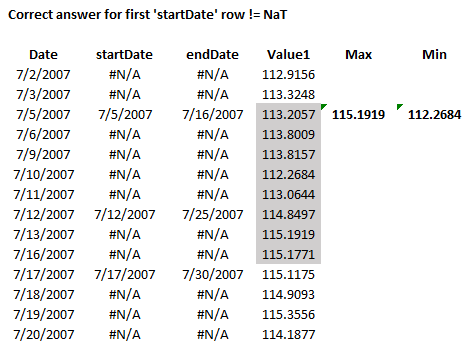
I have a pandas df (first 25 rows).
{'startDate': {Timestamp('2007-07-02 00:00:00'): NaT, Timestamp('2007-07-03 00:00:00'): NaT, Timestamp('2007-07-05 00:00:00'): Timestamp('2007-07-05 00:00:00'), Timestamp('2007-07-06 00:00:00'): NaT, Timestamp('2007-07-09 00:00:00'): NaT, Timestamp('2007-07-10 00:00:00'): NaT, Timestamp('2007-07-11 00:00:00'): NaT, Timestamp('2007-07-12 00:00:00'): Timestamp('2007-07-12 00:00:00'), Timestamp('2007-07-13 00:00:00'): NaT, Timestamp('2007-07-16 00:00:00'): NaT, Timestamp('2007-07-17 00:00:00'): Timestamp('2007-07-17 00:00:00'), Timestamp('2007-07-18 00:00:00'): NaT, Timestamp('2007-07-19 00:00:00'): NaT, Timestamp('2007-07-20 00:00:00'): NaT, Timestamp('2007-07-23 00:00:00'): NaT, Timestamp('2007-07-24 00:00:00'): NaT, Timestamp('2007-07-25 00:00:00'): NaT, Timestamp('2007-07-26 00:00:00'): NaT, Timestamp('2007-07-27 00:00:00'): NaT, Timestamp('2007-07-30 00:00:00'): NaT, Timestamp('2007-07-31 00:00:00'): NaT}, 'endDate': {Timestamp('2007-07-02 00:00:00'): NaT, Timestamp('2007-07-03 00:00:00'): NaT, Timestamp('2007-07-05 00:00:00'): Timestamp('2007-07-16 00:00:00'), Timestamp('2007-07-06 00:00:00'): NaT, Timestamp('2007-07-09 00:00:00'): NaT, Timestamp('2007-07-10 00:00:00'): NaT, Timestamp('2007-07-11 00:00:00'): NaT, Timestamp('2007-07-12 00:00:00'): Timestamp('2007-07-25 00:00:00'), Timestamp('2007-07-13 00:00:00'): NaT, Timestamp('2007-07-16 00:00:00'): NaT, Timestamp('2007-07-17 00:00:00'): Timestamp('2007-07-30 00:00:00'), Timestamp('2007-07-18 00:00:00'): NaT, Timestamp('2007-07-19 00:00:00'): NaT, Timestamp('2007-07-20 00:00:00'): NaT, Timestamp('2007-07-23 00:00:00'): NaT, Timestamp('2007-07-24 00:00:00'): NaT, Timestamp('2007-07-25 00:00:00'): NaT, Timestamp('2007-07-26 00:00:00'): NaT, Timestamp('2007-07-27 00:00:00'): NaT, Timestamp('2007-07-30 00:00:00'): NaT, Timestamp('2007-07-31 00:00:00'): NaT}, 'Value1': {Timestamp('2007-07-02 00:00:00'): 112.9156, Timestamp('2007-07-03 00:00:00'): 113.3248, Timestamp('2007-07-05 00:00:00'): 113.2057, Timestamp('2007-07-06 00:00:00'): 113.8009, Timestamp('2007-07-09 00:00:00'): 113.8157, Timestamp('2007-07-10 00:00:00'): 112.2684, Timestamp('2007-07-11 00:00:00'): 113.0644, Timestamp('2007-07-12 00:00:00'): 114.8497, Timestamp('2007-07-13 00:00:00'): 115.1919, Timestamp('2007-07-16 00:00:00'): 115.1771, Timestamp('2007-07-17 00:00:00'): 115.1175, Timestamp('2007-07-18 00:00:00'): 114.9093, Timestamp('2007-07-19 00:00:00'): 115.3556, Timestamp('2007-07-20 00:00:00'): 114.1877, Timestamp('2007-07-23 00:00:00'): 114.5373, Timestamp('2007-07-24 00:00:00'): 112.5511, Timestamp('2007-07-25 00:00:00'): 112.7817, Timestamp('2007-07-26 00:00:00'): 110.1111, Timestamp('2007-07-27 00:00:00'): 107.9464, Timestamp('2007-07-30 00:00:00'): 109.6351, Timestamp('2007-07-31 00:00:00'): 108.4002}}
The index, 'Date', is dt and is continuous daily data. I have two other dt cols, 'startDate' and 'endDate'. For each row in 'startDate' and 'endDate' that is != NaT I need to find the max and min of 'Value1' between startDate and endDate. Each 'startDate' and 'endDate' is in the index.
I cannot delete NaT's or I lose rows that could contain the max/min.
How can I do this?
CodePudding user response:
Try:
df.apply(lambda row: df.loc[row['startDate'] : row['endDate'], 'Value1'].max(),
axis=1)
For min - just replace max with min.
CodePudding user response:
I answered my own question. Apologize for all the text and formatting but maybe helpful to someone:
Keep the event-based startDate and endDate data in a seperate df ('df2') from the df ('df') containing continuous data from which you want to search for max/min.
Perform searchsorted and get the corresponding df2 values for both endpoints in df.
s1 = dfT.reindex(np.searchsorted(df2['entryDate'], df['Date'], side='right')-1)s2 = dfT.reindex(np.searchsorted(df2['exitDate'], df['Date'], side='right')-1)
This produces a unique index per event but spread across all rows in df.Drop indexes in s1 and s2 and concat to get both event indices together.
s1 = s1.reset_index()s1 = pd.concat([s1, s2], axis=1)Determine where the indices are the same. These are dates in the continuous data outside of event startDate-endDate windows and should be removed. s1['sameIDX'] = np.where((s1['entryIdx'] == s1['exitIdx']), 1, 0) s1 = s1[(s1['sameIDX'] == 0)]
Concat s1 with the continuous data (df).
Groupby 'uniqueIdx' to get max/mins lows = s1.groupby('uniqueIdx').min()['Value1'] highs = s1.groupby('uniqueIdx').max()['Value1']
Join with event df to add max/mins to events. df2 = pd.concat([df2, lows], axis=1) df2 = pd.concat([df2, highs], axis=1)